Sidekiq から Karafka へ:Honeybadger のシームレスなバックグラウンド ジョブの移行
バックグラウンド タスクは、Web アプリケーションの規模を検討する際の中核となる柱の 1 つです。基本的な考え方は単純です。クライアントが Web アプリケーションにリクエストを送信し、そのリクエストを処理する際に、アプリは時間のかかるいくつかのタスクを実行します。クライアントに迅速に応答できるようにするために、アプリはバックグラウンド ジョブをバックグラウンド処理システムのキューに入れます。バックグラウンド処理には、計算や I/O 操作などのすべての重労働が割り当てられます。バックグラウンド ジョブを効果的に利用することは、Web アプリケーションを拡張する際の最も重要な構成要素の 1 つです。
Rails 開発者として、私たちは、さまざまな長所、短所、さらにはバックエンド データベースを備えたいくつかの素晴らしいライブラリから選択できることに恵まれています。これらのライブラリを使用すると、面倒な作業を簡単にオフロードできるため、アプリケーションの応答が速くなり、より少ないリソースでより多くのユーザーにサービスを提供できるようになります。
最近まで、Honeybadger のバックグラウンド処理ジョブの大部分を実行するために Sidekiq を使用していました。これは、非常に高速なユーザー エクスペリエンスと、取り込んだ大量のデータを処理するための堅牢なパイプラインを維持するのに役立ちました。
Sidekiq ではどのような点が不足していますか?
Redis にはその信頼性にもかかわらず、いくつかの制限があります。最近まで、エラー追跡エンドポイントの取り込み処理を含むすべてのジョブ処理に Sidekiq を使用していました。エラー トラフィックは非常に変化しやすいです。多くの場合、キュー内のジョブの数は 10 倍または 20 倍になり、自動スケーリングで十分なワーカーが追いつくまで大量のバックログが発生します。しかし、より大きな問題は、ElastiCache クラスターのメモリ枯渇でした。
ElastiCache クラスターを通過するジョブ トラフィックが十分にあったため、ダウンストリーム処理で大幅な遅延が発生すると、クラスターのメモリが不足する危険がありました。キュー以外のデータを保存するために別のクラスターを使用していますが、時間が経つにつれて、キュー以外のデータがプライマリ クラスターにも表示され、メモリ不足エラーが発生した場合に削除される可能性があります。しかし、より重要な問題は、クラスタのメモリが不足したときに新しいジョブを受け入れることができないことでした。
二次的な問題は、Redis/ElastiCache が volatile-lru を使用することです。 デフォルトでは立ち退きポリシー。この結果、メモリの使用量が多くなると、Redis は TTL が設定された最も最近使用されていないデータを削除します。ある時点で、Honeybadger ではメモリ使用量が非常に高く、意図しないときに Redis がキャッシュをクリアし始めるというイベントが発生しました。幸いなことに、削除されたデータは再現可能だったので (TTL であるため)、永続的なデータは失われませんでした。
それでも、これには対処する必要がある 1 つの疑問が残りました。同様のイベントが発生し、再構築できなかったデータが失われ始めたらどうなるでしょうか?顧客データを決して失わないようにするにはどうすればよいでしょうか?顧客エラーデータの処理は当社のビジネスの中核であるため、データ損失に強いシステムが必要です。
データの取り込みに Kafka を使用する
Kafka は、スケーラビリティと復元力の両方を提供する分散イベント パイプラインです。最近リリースした Insights により、私たちはイベント データを処理するインフラストラクチャとして Kafka を立ち上げる豊富な経験を積みました。その後、同じテクノロジー スタックを使用してエラー取り込みデータを処理したいと考えました。私たちは、Kafka を使用することで、より優れた拡張性とより手頃なコストを備えた冗長ストレージを実現することを目指しました。
私たちは Insights 用に独自の AWS MSK クラスターを実行していたため、インフラストラクチャと自動スケーリングのセットアップがすでに完了していました。これは、いくつかのトピックを設定し、Sidekiq ワーカーと同じコードを実行するいくつかのコンシューマを作成するだけで済むことを意味しました。コンセプトは非常にシンプルだったので、Kafka コンシューマーの微調整にもっと集中できるようになりました。
Sidekiq から Karafka への移行
Honeybadger は雄大な一枚岩として設計されており、Karafka はその同じアーキテクチャを維持するのに役立ちます。私たちはすでに Karafka を使用して Insights データの一部を処理しているため、いくつかの新しいコンシューマーを追加するのは簡単な作業でした。
Karafka と Sidekiq の主な違いの 1 つは、ジョブの取得方法です。 Karafka を使用すると、ジョブはバッチ化され、単一のコンシューマー実行でまとめて処理されます。コンシューマでは、メッセージの配列を反復処理し、Sidekiq ワーカーをインラインで実行できます。
class NoticeConsumer < ApplicationConsumer
def consume
messages.each do |message|
NoticeWorker.new.perform(message.payload)
end
end
end
考慮しなければならないもう 1 つの違いは、エラー処理がどのように機能するかです。 Sidekiq では、各ジョブがアトミックであるため、ワーカーは再試行と失敗コールバックを通じて独自のエラーを処理します。 Kafka のバッチ動作により、エラーを処理するためのオプションがさらに増えました。最も注目すべき点は、Karafka が Dead Letter Queue と呼ばれるメカニズムを提供していることです。これにより、エラー処理をバッチまたは個別に指定できます。
dead_letter_queue(
topic: "ingestion.errors.dead",
max_retries: 5,
independent: true
)
Karafka コンシューマーは、個々のメッセージの処理に失敗するたびに、再処理を 5 回試行します。 5 回目の試行に失敗した場合、メッセージは指定されたトピックに送信されます。 independent: true このオプションは、バッチ全体ではなく、失敗したメッセージのみを DLQ に送信する必要があることをコンシューマーに指示します。
Karafka のモニタリングとスケーリング
結局のところ、Karafka コンシューマーの監視とスケーリングは非常に複雑です。 AWS/MSK と Karafka の両方から追跡できるものはたくさんあり、システムを調整するために回転できるノブもたくさんあります。コードが何を行っているか、データ フローの動作に細心の注意を払う必要があります。
AWS CloudWatch を使用して多くのことを監視しますが、ここでは私たちが確認している Kafka 固有のメトリクスをいくつか示します。
- SumOffsetLag — 指定されたトピックとコンシューマ グループの場合、これはすべてのパーティションにわたるすべてのオフセット ラグの合計です。
- 推定最大タイムラグ — 指定されたトピックと消費者グループの場合、 これは推定されます。 すべてのパーティションを現在のオフセットに追いつくのにかかる時間
Karafka はいくつかの優れたインスツルメンテーションも提供しますが、このデータは自分で公開して保存する必要があります。
- 処理遅延 * — この値は、消費されるメッセージのバッチごとに使用できます。これは、Kafka が Kafka からメッセージを取得して処理を開始するまでにかかった時間を示します。
- 消費ラグ * — この値はprocessing_lagに似ています。 ただし、バッチの最後のメッセージが Kafka システムに入ってから、コンシューマーがメッセージの処理を開始するまでの時間です。
- 期間 * — これは、コンシューマがメッセージのバッチ全体を処理するのにかかる時間です。
結局のところ、Sidekiq プロセスのスケーリングは、Karafka コンシューマ プロセスのスケーリングとは大きく異なります。 Sidekiq の並列化を高める場合は、Redis インスタンスが処理できるプロセスをさらに追加できます。 Kafka では、トピック内のパーティションごとに最大 1 つのプロセスを持つ必要があります。一般的な経験則として、Kafka コンシューマーは複数のパーティションに割り当てられる可能性があるため、計画よりも多くのパーティションを用意する必要があります。
もう 1 つ覚えておくべきことは、Kafka コンシューマーのスケールアップとスケールダウンは非常に時間のかかる操作になる可能性があるということです。コンシューマ グループにコンシューマを追加または削除するには、グループ自体のバランスを再調整する必要があります。これは、必要に応じてパーティションを再割り当てすることを意味します。再割り当て中、コンシューマーはメッセージの処理を停止します。 sticky-cooperative を使用すると、この問題をある程度軽減できますが、 割り当てを行う場合、通常、リソースを過剰にプロビジョニングすることで、可能であればリバランスを避けたいと考えます。
現在 SumOffsetLag を監視しています スケーリング指標の 1 つとして。注意すべき重要な点は、リバランス中、このメトリクスはレポートされないことです。したがって、ご想像のとおり、リバランス期間中、この指標はリバランスが終了するまで大幅に増加します。これが、スケーリングを最小限に抑えることが重要なもう 1 つの理由です。
Honeybadger の Karafka の次の予定は何ですか?
私たちは 1 か月間以上、Kafka/Karafka の実装を 100% で実行してきましたが、かなり満足していると言っても過言ではありません。それでも、必要に応じてボタンを押すだけでいつでも Sidekiq にフォールバックできることは素晴らしいことです。これにより、これらのシステムのいずれかでメンテナンス作業が必要になった場合の復元力がさらに高まります。
Sidekiq から Karafka に移行する過程で、Kafka と Karafka の使用についてさらに多くのことを学びました。 Honeybadger gem の最新バージョンに更新していない場合は、ぜひチェックしてください。 karafka プラグインにいくつかの新機能を追加しました。 Insights を有効にすると、Kafka システムの全体的な健全性をより良く把握できるよう、Gem は重要な統計のいくつかの追跡を開始します。
さらに、このデータを視覚化し、Kafka コンシューマーがどのように行動しているかをより深く理解できるようにする Insights Karakfa ダッシュボードが提供されるようになりました。 Karafka ダッシュボードでは、プラグインに対してメトリクスを有効にする必要があります。これを行うには、honeybadger.yml に次の構成を追加します。 :
karafka:
insights:
metrics: true
ダッシュボードのサンプルは次のとおりです。
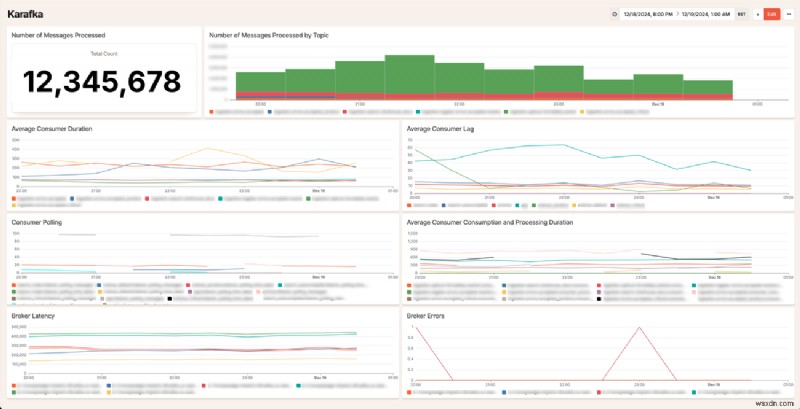
私たちは、お客様がこのデータを使用して独自の Kafka システムを改善する方法を見るのを楽しみにしています。 Sidekiq から Karafka への移行方法や、Kafka の一般的な使用方法についてご質問がございましたら、お気軽にお問い合わせください。
-
AppSignal が Alpine Linux ARM をサポート:安心してサーバーを監視
本日、Alpine Linux を実行するマシンの ARM サポートを開始します。この機能は、Ruby および Elixir ユーザーが利用できます。将来的には、Node.js パッケージに Alpine Linux ARM のサポートを追加したいと考えています。 ARM CPU アーキテクチャはますます人気が高まっています。これは開発マシンや運用サーバーに電力を供給するため、サポートするオペレーティング システムのリストにこれを追加することにしました。 インストール手順 以前と同じ方法でパッケージをインストールできます。 ARM マシンは自動的に検出され、一致する拡張機能とエージェントが
-
Rubyネットワークプログラミング
Rubyでカスタムネットワーククライアントとサーバーを作成しますか?または、それがどのように機能するかを理解しますか? 次に、ソケットを処理する必要があります。 このルビーネットワークプログラミングのツアーに参加してください 基本を学び、Rubyを使用して他のサーバーやクライアントと会話を始めましょう! では、ソケットとは何ですか ? ソケットは通信チャネルのエンドポイントであり、クライアントとサーバーの両方がソケットを使用して通信します。 動作方法は非常にシンプルです : 接続が確立されると、データをソケットに入れることができます。データはもう一方の端に送られ、そこで受信者はソケ