Rails でクラスター間の関連付けをマスターする:データベースのパーティショニングの課題を克服する
Rails フレームワークの利点の 1 つは、モデル内で Ruby on Rails の関連付けを利用できることです。これらの関連付けにより、快適な構文を使用してコード内のレコードのコレクションにアクセスできるようになり、基礎となる SQL クエリを記述する必要がなくなりました。この抽象化は、すべてのデータが 1 か所に存在する限り保持されます。テーブルが別々のデータベース クラスタに分散されると、特定の関連付けタイプが機能しなくなります。
この記事では、境界がどこにあるのか、そしてその境界内で動作するために Rails が提供するものを正確に説明します。まず、問題が発生する理由と、Rails のどの関連付けが影響を受けるのかを説明し、複数のクラスターと多対多の関係をサポートするデータベース構成とモデル階層に進みます。そこから、さまざまなデータ アクセス パターンがそれぞれその分解とどのように相互作用するかを説明します。
特にマルチデータベースのセットアップをカバーする Rails 関連付けチュートリアルをお探しの場合は、これが最適です。他にも多くのことについて説明しますので、しばらくお待ちください。
データベースが異なるクラスタに分割される理由
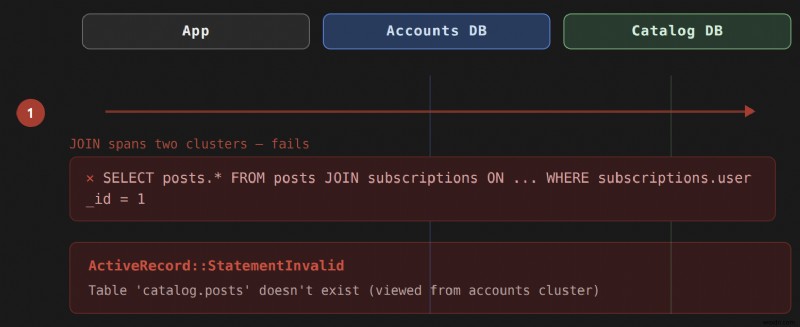
Rails アプリケーションがすべてのデータを 1 つのデータベースに保存すると、アクティブ レコードの関連付けが透過的に処理されるため、基礎となる SQL について考える必要はありません。データが複数のデータベース クラスターにまたがって存在する瞬間、その透明性は失われます。 JOIN 両方のテーブルが同じデータベース サーバーに存在する必要があります。クラスタ全体でこれを試行すると、ActiveRecord::StatementInvalid が生成されます。 このようなエラー:
ActiveRecord::StatementInvalid (Table 'people_cluster.humans' doesn't exist)
これは設定ミスではありません。これは物理的な厳しい制約です。データベース サーバーは JOIN できません。 彼らがホストしていないテーブルに対して。この問題は has_many :through で発生します。 と has_one :through これらは中間 JOIN を生成する関連付けタイプであるため、 クエリ。直接 has_many または belongs_to 関係には結合が必要ないため、変更を加えることなくクラスタ間で機能します。
いつかを理解する この境界に到達することが最初のステップです。 User の場合 accounts に住んでいます データベースと Post content に住んでいます データベース、User has_many :posts 正常に動作します。ただし、中間の Subscription を追加すると、 billing のモデル データベースに User has_many :posts, through: :subscriptions を定義します 、Rails は subscriptions に参加しようとします。 と posts 単一のクエリで。ここで、クラスターの境界が問題になります。
3 層データベース構成
モデル コードを記述する前に、データベース構成にマルチクラスター レイアウトを反映する必要があります。 Rails は config/database.yml で 3 層構造を使用します。 この目的のために。各トップレベルの環境キーにはネストされたデータベース名が含まれており、それぞれにそのクラスターの接続の詳細が含まれています。
# config/database.yml
default: &default
adapter: postgresql
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
development:
primary:
<<: *default
database: myapp_primary_dev
accounts:
<<: *default
database: myapp_accounts_dev
migrations_paths: db/accounts_migrate
content:
<<: *default
database: myapp_content_dev
migrations_paths: db/content_migrate
production:
primary:
<<: *default
database: myapp_primary_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
accounts:
<<: *default
database: myapp_accounts_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
content:
<<: *default
database: myapp_content_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
migrations_paths Rails ジェネレーターと db:migrate が必要な場合、キーはオプションではありません。 移行を正しいディレクトリにルーティングします。これがないと、すべての移行はデフォルトで db/migrate になります。 そしてプライマリデータベースに適用されます。各セカンダリ データベースには、Rails モデルが継承する対応する抽象レコード クラスも必要です。 --database を渡すと、ジェネレーターがこれを自動的に処理します。 フラグ:
rails generate model Subscription plan:string --database accounts
これにより、AccountsRecord が生成されます。 クラスがまだ存在しない場合は、生成された Subscription モデルはそこから継承します。
抽象レコード クラスと接続ルーティング
抽象レコード クラスは、Rails がクエリを正しいクラスターにルーティングするために使用するメカニズムです。それぞれが connects_to を呼び出します 書き込みおよび読み取り操作のためにどのデータベースにマップするかを宣言します。通常、アプリケーションにはこの階層に 3 つの層があります。
# app/models/application_record.rb
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary }
end
# app/models/accounts_record.rb
class AccountsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :accounts, reading: :accounts }
end
# app/models/content_record.rb
class ContentRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :content, reading: :content }
end
ユーザー モデルは、この階層を理解するための優れたアンカーです。 accounts に存在します クラスタであり、AccountsRecord から継承されます。 。 content のモデル クラスタは ContentRecord から継承します 。それ以外はすべて ApplicationRecord から継承します。 そしてプライマリデータベースにヒットします。この継承チェーンは、Active Record がクエリの実行時に使用する接続プールを決定する方法です。 connects_to を呼び出したクラスが見つかるまで、クラス階層を上っていきます。 。 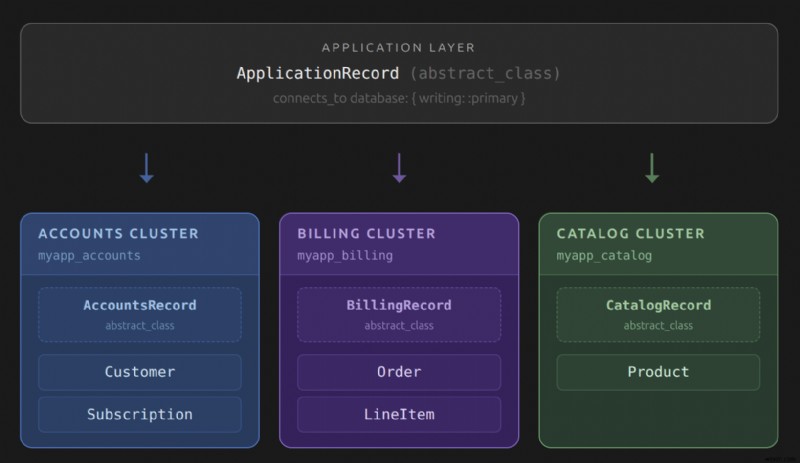
よくある間違いは、establish_connection を呼び出すことです。 抽象クラスを使用するのではなく、個々のモデルで。各 establish_connection 呼び出しは別の接続プールを開きます。 accounts に 50 個のモデルがある場合 データベース、それぞれ establish_connection を呼び出します の場合、同じサーバーを指す接続プールが 50 個になることになります。抽象クラスは、そこから継承するすべてのモデル間で単一のプールを共有することで、この問題を解決します。
Rails でのクラスタ間の関連付けが実際にどのように機能するか
disable_joins: true オプションは、through を作成するための直接のメカニズムです。 関連するテーブルが異なるクラスターに存在する場合、関連付けは機能します。 Rails has_many は最も一般的に使用される関連付けタイプであり、クラスター境界の影響を最も直接受けます。 Rails は関連付けでこのオプションを検出すると、単一の JOIN を破棄します。 クエリ戦略を使用し、代わりに 2 つ (またはそれ以上) の連続した SELECT を発行します。 ステートメント、最初のクエリからの ID を WHERE ... IN (...) にパイプします。 2 番目の句。
ここでは、3 つのクラスターにまたがる具体的なモデルのセットアップを示します。以下のモデル設定は多対多の関係であり、ユーザーはサブスクリプションを通じて投稿に接続します。これは、クラスタ間の問題を最も直接的に露呈するパターンです。
# app/models/user.rb - lives in the accounts database
class User < AccountsRecord
has_many :subscriptions
has_many :posts, through: :subscriptions, disable_joins: true
end
# app/models/subscription.rb - lives in the accounts database
class Subscription < AccountsRecord
belongs_to :user
has_many :posts
end
# app/models/post.rb - lives in the content database
class Post < ContentRecord
belongs_to :subscription
end
user.posts を呼び出すとき 、Rails は、単一の JOIN の代わりにこのクエリのペアを生成します。 :
-- Query 1: fetch subscription IDs from the accounts cluster
SELECT "subscriptions"."id"
FROM "subscriptions"
WHERE "subscriptions"."user_id" = 1
-- Query 2: fetch posts from the content cluster using those IDs
SELECT "posts".*
FROM "posts"
WHERE "posts"."subscription_id" IN (4, 7, 12)
最初のクエリは accounts に対して実行されます。 データベースを使用して主キーを収集します。 2 番目は content に対して実行されます。 。 Rails は外部キー user_id に従って関係を解決します。 サブスクリプションと subscription_id について 2 つのクラスターにわたる投稿上で。最初のクエリはサブスクリプションから主キー値を収集し、それらを IN に渡します。 2 番目のクエリの句。どちらのクエリもクラスター間結合を試みません。 Rails は、最終的な結果セットをアプリケーション メモリにアセンブルします。 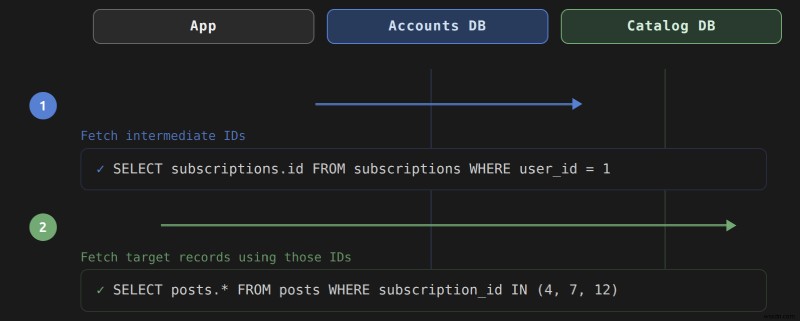
 同じオプションは
同じオプションは has_one :through でも同様に機能します。 :
# app/models/user.rb
class User < AccountsRecord
has_one :profile
has_one :avatar, through: :profile, disable_joins: true
end
# app/models/profile.rb - accounts database
class Profile < AccountsRecord
belongs_to :user
has_one :avatar
end
# app/models/avatar.rb - content database
class Avatar < ContentRecord
belongs_to :profile
end
user.avatar 2 つのクエリを実行します。1 つは profile_id を取得するクエリです。 、もう 1 つはコンテンツ クラスターからアバター レコードを取得するためです。
disable_joinsの場合 明示的に設定する必要があります
Rails はクラスター境界を自動的に検出し、disable_joins を挿入しません。 あなたのために。 Active Record での関連付けの読み込みは遅延します。アソシエーションの SQL は、アソシエーションが実際にトリガーされたときではなく、モデル上でアソシエーションが定義された時点で決定されます。 user.posts までに が実行されると、Rails は JOIN を使用するかどうかをすでに決定しています。 または、関連付け宣言に基づいて別のクエリを実行します。
これは、すべての through を意味します。 クラスター境界を越える関連付けには disable_joins: true が必要です
モデルを監査する実際的な方法は、through: を探すことです。 ソース モデルとターゲット モデルが異なる抽象レコード クラスから継承される関連付け。 User < AccountsRecord の場合 および Post < ContentRecord 、次に has_many :posts, through: :subscriptions disable_joins: true が必要です Subscription の場所に関係なく 生きています。
クラスタ間での積極的な読み込み
disable_joins このオプションは関連付けのロード方法に影響しますが、即時ロード戦略がクラスター間データと対話する方法は変わりません。この区別を理解することは、複数データベース設定で N+1 クエリを回避するために重要です。
eager_load クラスタ間の関連付けの対象外です。 LEFT OUTER JOIN が生成されます。 、通常の JOIN と同じ物理的な制限があります。 、両方のテーブルが同じサーバー上に存在する必要があります。 User.eager_load(:posts) を試行すると 投稿が別のクラスターに存在する場合、同じ StatementInvalid が取得されます。 エラー。
preload は正しい戦略です。各関連付けに対して個別のクエリを発行し、Ruby で関係を組み立てます。これは disable_joins と構造的に同じです。 単一のレコードに対して実行します。違いはスケールです:preload ロードされたすべての親レコードに対して 2 番目のクエリをバッチ処理します。
# This works across clusters.
# Query 1: SELECT "users".* FROM "users"
# Query 2: SELECT "posts".* FROM "posts" WHERE "posts"."subscription_id" IN (...)
users = User.preload(:posts).all
users.each do |user|
user.posts.each { |post| puts post.title } # No additional queries fired
end
includes preload に委任する場合に機能します。 内部的には、関連付けられたテーブルを参照する条件がない場合にデフォルトで実行されます。 .where を追加すると 関連するテーブルの列に触れる句、includes eager_load に切り替わります 動作が異なり、クラスタ間で失敗します。どの戦略に迷ったら includes preload を選択し、明示的に使用します。
# includes delegates to preload here, works across clusters
User.includes(:posts).all
# includes switches to eager_load because of the where clause, fails across clusters
User.includes(:posts).where("posts.published = ?", true)
# Use preload + a separate where for cross-cluster filtering
User.preload(:posts).all.select { |u| u.posts.any?(&:published?) }
# Or filter in application code after loading
スコープ指定された関連付けとクラスタ間フィルタリング
マルチデータベース設定におけるより微妙な相互作用の 1 つは、スコープ付きの関連付けです。 has_many でスコープを定義する場合 クラスタをまたがる場合、スコープの SQL はソースではなくターゲット データベースに対して実行されます。
class User < AccountsRecord
has_many :subscriptions
has_many :published_posts,
-> { where(published: true) },
through: :subscriptions,
source: :posts,
class_name: "Post",
disable_joins: true
end
where(published: true) 句は 2 番目のクエリ (content に対して実行されるクエリ) に追加されます。 データベース。これは正しい動作であり、スコープがターゲット テーブルの列を問題なく参照できることを意味します。実行できないのは、そのスコープ内の中間テーブルから列を参照することです。これは、スコープ付きクエリが実行されるまでに中間クエリがすでに完了しているためです。
# This will fail because subscriptions.active is not a column in the content database
has_many :active_posts,
-> { where("subscriptions.active = ?", true) },
through: :subscriptions,
source: :posts,
disable_joins: true
代わりに中間関連付けにスコープを追加して、中間レコードをフィルタリングします。
class User < AccountsRecord
has_many :active_subscriptions, -> { where(active: true) }, class_name: "Subscription"
has_many :active_posts, through: :active_subscriptions, source: :posts, disable_joins: true
end
subscriptions.active でフィルタリングします。 最初のクエリで accounts に対して発生します。 データベースにアクセスし、アクティブなサブスクリプションの ID のみが 2 番目のクエリに渡されます。
水平シャーディングとシャード間の関連付け
tenant_id のようなパーティション キーに基づいて 1 つの論理データベースを複数のサーバーに分割する クラスタ間問題に 2 番目の次元が導入されます。 disable_joins このメカニズムは引き続き適用されますが、接続ルーティングはより複雑になります。
Rails は connected_to を提供します リクエスト内でシャード間を切り替える場合:
ActiveRecord::Base.connected_to(role: :writing, shard: :shard_one) do
User.find(1) # Hits shard_one
end
関連付けがクラスターとシャードの両方にまたがる場合、シャード コンテキストと disable_joins の両方を確認する必要があります。 オプションが用意されています。 User shard_one で 別の content にある投稿にアクセスする データベースには依然として同じ 2 つのクエリ分解が必要です。
Rails 8 では、実行時にシャード トポロジについての推論を容易にするイントロスペクション メソッドが追加されました。
class ShardedBase < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
shard_one: { writing: :shard_one },
shard_two: { writing: :shard_two }
}
end
class User < ShardedBase; end
User.shard_keys # => [:shard_one, :shard_two]
User.sharded? # => true
ShardedBase.connected_to_all_shards do
User.current_shard # Yields :shard_one, then :shard_two
end
connected_to_all_shards すべてのシャードにわたってレコードを処理する必要があるバックグラウンド ジョブに特に役立ちます。各シャードを順番に繰り返し、ブロック実行ごとに接続コンテキストを切り替えます。
テナントベースのシャーディングの場合、lock: true シャード切り替えのデフォルトにより、リクエスト中の偶発的なテナントホッピングが防止されます。これは安全メカニズムです。リクエストがテナントのシャードにルーティングされると、アプリケーション コードは明示的に lock: false を渡さない限り、別のテナントのシャードに切り替えることはできません。 。単一テナントのシャード内のクラスター間の関連付けでは、引き続き disable_joins が使用されます。 別のデータベース クラスタに接続する関連付けの場合。
クラスタ間の関連付けのテスト
マルチデータベース設定をテストするには、テスト環境が運用データベース トポロジを反映している必要があります。 Rails のテスト フレームワークはこれをサポートしていますが、構成は明示的に行う必要があります。
database.yml の各データベース test が必要です 環境ブロック。フィクスチャと工場ベースのテスト データは、正しいデータベースをターゲットにする必要があります。 User の場合 ファクトリーは accounts にレコードを作成します データベースと Post ファクトリーは content で作成します。 、両方のレコードが同じテスト トランザクション内のそれぞれのデータベースに存在する場合にのみ、それらの間の関連付けが機能します。
Rails はデフォルトで各テストをトランザクションにラップしますが、そのトランザクションは接続ごとです。複数のデータベースがある場合、各接続は独自のトランザクションを取得します。これは、テストのクリーンアップ (各テストの終了時の自動ロールバック) が各データベースで独立して行われることを意味します。テストで User が書き込まれた場合 accounts へ と Post content へ 、両方ともロールバックされますが、これはテスト フレームワークが両方の接続を認識している場合に限ります。
fixtures モデルが正しい抽象クラスから継承する場合、宣言はこれを自動的に処理します。ファクトリベースのセットアップ (FactoryBot、Fabricator) の場合は、各ファクトリの create を確認してください。 戦略は、モデル自身の connects_to を使用することで、適切なデータベースにアクセスします。 ルーティングが機能します。
# spec/factories/users.rb
FactoryBot.define do
factory :user do
# User inherits from AccountsRecord and writes to accounts DB automatically
name { Faker::Name.name }
end
end
# spec/factories/posts.rb
FactoryBot.define do
factory :post do
# Post inherits from ContentRecord and writes to content DB automatically
association :subscription
title { Faker::Lorem.sentence }
end
end
クラスタ間の関連付けが予想される数のクエリを実行していることを確認するには、sql.active_record にサブスクライブします。 通知:
# spec/support/query_counter.rb
module QueryCounter
def assert_query_count(expected, &block)
count = 0
callback = ->(_name, _start, _finish, _id, payload) do
count += 1 unless payload[:name] == "SCHEMA" || payload[:sql].start_with?("EXPLAIN")
end
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
assert_equal expected, count, "Expected #{expected} queries, got #{count}"
end
end
has_many :through disable_joins: true を使用 1 つのレコードに対して、正確に 2 つのクエリが生成されるはずです。 1 が表示される場合、結合はまだ試行中です (実稼働環境では別のサーバーに対して失敗します)。 N+1 が表示される場合、熱心な読み込みが期待どおりに機能していません。
いくつかの注意事項
disable_joins 関連読み込みの問題は解決されますが、クエリ チェーンには適用されません。 .where をチェーンすることはできません 、.order 、または .group 単一のアクティブ レコード リレーションのクラスタ全体で列を参照する句:
# This does not work, you cannot filter products by order columns across clusters
customer.purchased_products.where("orders.total > ?", 100)
複数のクラスター内のデータに基づいてフィルターまたは並べ替える必要があるクエリの場合は、手動で分解します。必要な ID または値を 1 つのクラスタからフェッチし、それらを他のクラスタに対するクエリへの入力として使用します。
high_value_order_ids = Order.where(customer_id: customer.id)
.where("total > ?", 100)
.pluck(:id)
line_item_product_ids = LineItem.where(order_id: high_value_order_ids).pluck(:product_id)
products = Product.where(id: line_item_product_ids)
これは disable_joins と同じ分解です。 内部的に実行されますが、明示的に実行されるため、各段階でフィルタリングを適用できます。これはより冗長ですが、クラスタ境界を Rails 構文の関連付けの背後に隠すのではなく、コード内で表示できるようにします。
編集者注:この投稿はもともと 2023 年 1 月に公開され、正確性を期すために更新されました。
-
RailsでFlashメッセージを使用する方法
フラッシュメッセージとは何ですか? フラッシュメッセージは、Railsアプリケーションのユーザーと情報を伝達する方法であり、ユーザーはアクションの結果として何が起こるかを知ることができます。 メッセージの例 : 「パスワードが正しく変更されました」(確認) 「ユーザーが見つかりません」(エラー) これらのフラッシュメッセージをコントローラーに設定してから、ビューにレンダリングします。その後、ユーザーはそれに応じて行動できます。 これがどのように機能するかを正確に学びましょう! フラッシュメッセージの使用方法 flashを使用して、これらの通知メッセージを操作できます ヘルパーメソ
-
マスター Ruby:スキルを向上させ、印象的なポートフォリオを構築するためのトップ プロジェクト
Ruby は、そのシンプルさから人気があり、広く使用されているプログラミング言語です。さまざまなプロジェクトに役立ちます。 Twitter、Hulu、AirBnB などの Web サイトを開発することが目標の場合、Ruby プログラミングを学ぶことが重要です。 Ruby プロジェクトで練習してスキルを磨き、キャリア目標の達成に役立てることができます。 このガイドでは、Ruby プログラミング スキルを開発するために使用できる、スキル レベルごとのプロジェクトのアイデアをいくつか紹介します。現在ブートキャンプ プログラムまたは Ruby のオンライン コースに登録している場合、これらのプロジェ