Rubyのニューラルネットワーク:それほど怖くない紹介
この投稿では、ニューラルネットワークの基本と、Rubyを利用してそれらを実装する方法を学びます。人工知能とディープラーニングに興味があるが、開始方法がわからない場合は、この投稿が最適です。重要な概念を強調するために、簡単な例を見ていきます。 Rubyを使用して多層ニューラルネットワークを作成することはほとんどありませんが、単純さと読みやすさのために、何が起こっているのかを理解するための優れた方法です。まず、一歩下がって、どうやってここにたどり着いたかを見てみましょう。
 映画ExMachniaの静止画。写真クレジット
映画ExMachniaの静止画。写真クレジット
Ex Machinaは2014年に公開された映画です。Googleでタイトルを調べると、映画のジャンルが「ドラマ/ファンタジー」に分類されています。そして、私が最初に映画を見たとき、それは空想科学小説のようでした。
しかし、もっと長い間?
Googleで働く有名な未来派のレイカーツワイルに聞くと、2029年は、人工知能が有効なチューリングテスト(人間が機械/コンピューターと別の人間を区別できるかどうかを確認する実験)に合格する年になる可能性があります。 )彼はまた、特異性(コンピューターが人間の知性を超える場合)が2045年までに出現すると予測しています。
カーツワイルがこれほど自信を持っている理由は何ですか?
簡単に言えば、ディープラーニングは、ニューラルネットワークを利用して大量のデータから洞察を抽出する機械学習のサブセットです。ディープラーニングの実際のアプリケーションには、次のものがあります。-自動運転車-がんの検出-SiriやAlexaなどの仮想アシスタント-地震などの極端な気象イベントの予測
しかし、「ニューラルネットワーク」とは何ですか?
ニューラルネットワークの名前は、電気的および化学的信号を介して情報を処理および送信する脳細胞であるニューロンに由来しています。おもしろい事実:人間の脳は800億以上のニューロンで構成されています!
コンピューティングでは、ニューラルネットワークは次のようになります。
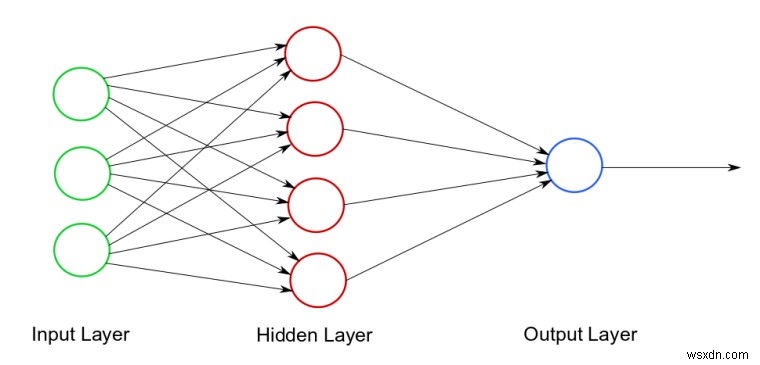 ニューラルネットワーク図の例。写真クレジット
ニューラルネットワーク図の例。写真クレジット
ご覧のとおり、3つの部分があります。1)入力層-初期データ2)非表示層-ニューラルネットワークは、1つ(またはそれ以上)の非表示層を持つことができます。ここですべての計算が行われます。 3)出力レイヤー-最終結果/予測
ニューラルネットワークは新しいものではありません。実際、最初の訓練可能なニューラルネットワーク(パーセプトロン)は、1950年代にコーネル大学で開発されました。ただし、主に元のモデルが1つの隠れ層のみで構成されていたため、ニューラルネットワークの適用性を取り巻く多くの悲観論がありました。 1969年に出版された本は、かなり単純な計算にパーセプトロンを利用することは非現実的であることを示しました。
ニューラルネットワークの復活は、コンピュータゲームに起因する可能性があります。コンピュータゲームでは、非常に強力なグラフィックスプロセッシングユニット(GPU)が必要になり、そのアーキテクチャはニューラルネットのアーキテクチャに非常に似ています。違いは、隠れ層の数です。今日トレーニングされたニューラルネットワークは、1つではなく、10、15、さらには50以上のレイヤーを使用しています。
例の時間!
これがどのように機能するかを理解するために、例を見てみましょう。 ruby-fannをインストールする必要があります 宝石。ターミナルを開き、作業ディレクトリに移動します。次に、以下を実行します。
gem install ruby-fann
新しいRubyファイルを作成します(私は私のneural-net.rbという名前を付けました )。
次に、Kaggleの「StudentAlcoholConsumption」データセットを利用します。こちらからダウンロードできます。 Googleスプレッドシート(または選択したエディタ)で「student-mat.csv」ファイルを開きます。これらを除くすべての列を削除します。-Dalc(1が非常に低く、5が非常に高い就業日のアルコール消費量)-Walc (1が非常に低く、5が非常に高い週末のアルコール消費量)-G3(0〜20の最終グレード)
ルビーファンの宝石を機能させるには、最終グレードの列をバイナリ(0または1)に変更する必要があります。この例では、10以下は「0」であり、10より大きいものは「1」であると想定します。使用しているプログラムに応じて、セルに数式を記述して、セルの値に基づいて値を1または0に自動的に変更できるようにする必要があります。 Googleスプレッドシートでは、次のようになります。
=IF(C3 >= 10, 1, 0)
このデータを.CSVファイルとして保存します(私はstudents.csvという名前を付けました )Rubyファイルと同じディレクトリにあります。
ニューラルネットワークには次のレイヤーがあります。-入力レイヤー:2ノード(平日のアルコール消費量と週末のアルコール消費量)-非表示レイヤー:6つの非表示ノード(これは開始するのに多少任意です。後でテストするときに変更できます)-出力レイヤー:1ノード(0または1のいずれか)
まず、ruby-fannを要求する必要があります gem、および組み込みのcsv 図書館。これをRubyプログラムの最初の行に追加します:
require 'ruby-fann'
require 'csv'
次に、CSVファイルから配列にデータをロードする必要があります。
# Create two empty arrays. One will hold our independent varaibles (x_data), and the other will hold our dependent variable (y_data).
x_data = []
y_data = []
# Iterate through our CSV data and add elements to applicable arrays.
# Note that if we don't add the .to_f and .to_i, our arrays would have strings, and the ruby-fann library would not be happy.
CSV.foreach("students.csv", headers: false) do |row|
x_data.push([row[0].to_f, row[1].to_f])
y_data.push(row[2].to_i)
end
次に、データをトレーニングデータとテストデータに分割する必要があります。 80/20分割はかなり一般的であり、データの20%がテストに使用され、80%がトレーニングに使用されます。ここでの「トレーニング」とは、モデルがこのデータに基づいて学習し、次に「テスト」データを使用して、モデルが結果をどの程度適切に予測するかを確認することを意味します。
# Divide data into a training set and test set.
testing_percentage = 20.0
# Take the number of total elements and multiply by the test percentage.
testing_size = x_data.size * (testing_percentage/100.to_f)
# Start at the beginning and end at the testing_size - 1 since arrays are 0-indexed.
x_test_data = x_data[0 .. (testing_size-1)]
y_test_data = y_data[0 .. (testing_size-1)]
# Pick up where we left off until the end of the dataset.
x_train_data = x_data[testing_size .. x_data.size]
y_train_data = y_data[testing_size .. y_data.size]
涼しい!データの準備が整いました。次は魔法です!
# Set up the training data model.
train = RubyFann::TrainData.new(:inputs=> x_train_data, :desired_outputs=>y_train_data)
RubyFann ::TrainDataオブジェクトを使用し、x_train_data,を渡します。 これは、私たちの平日と週末のアルコール消費量であり、y_train_data, これは、最終コースの成績に基づいて0または1です。
それでは、前に説明した隠れニューロンの数を使用して、実際のニューラルネットワークモデルを設定しましょう。
# Set up the model and train using training data.
model = RubyFann::Standard.new(
num_inputs: 2,
hidden_neurons: [6],
num_outputs: 1 );
OK、トレーニングする時間です!
model.train_on_data(train, 1000, 10, 0.01)
ここでは、trainを渡します 以前に作成した変数。 1000はmax_epochsの数を表し、10はレポート間のエラーの数を表し、0.1は目的の平均二乗誤差です。 1つのエポックは、データセット全体がニューラルネットワークを通過するときです。平均二乗誤差は、最小化しようとしているものです。これが何を意味するかについて詳しくは、こちらをご覧ください。
次に、モデルがテストデータに対して予測したものを実際の結果と比較することにより、モデルがどの程度うまく機能したかを知りたいと思います。このコードを利用することでこれを達成できます:
predicted = []
# Iterate over our x_test_data, run our model on each one, and add it to our predicted array.
x_test_data.each do |params|
predicted.push( model.run(params).map{ |e| e.round } )
end
# Compare the predicted results with the actual results.
correct = predicted.collect.with_index { |e,i| (e == y_test_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
# Print out the accuracy rate.
puts "Accuracy: #{((correct.to_f / testing_size) * 100).round(2)}% - test set of size #{testing_percentage}%"
プログラムを実行して、何が起こるか見てみましょう!
ruby neural-net.rb
エポックの出力がたくさん表示されるはずですが、下部に次のようなものが表示されます。
Accuracy: 56.82% - test set of size 20.0%
ああ、それはあまり良くありません!しかし、独自のデータポイントを考え出し、モデルを実行してみましょう。
prediction = model.run( [1, 1] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction.map{ |e| e.round }}"
prediction_two = model.run( [5, 4] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction_two.map{ |e| e.round }}"
ここに、2つの例があります。まず、平日と週末のアルコール消費量を1秒で渡します。私が賭けをしている人なら、この学生の最終成績は10(つまり、1)を超えると思います。 2番目の例では、アルコール消費量の高い値(5と4)が渡されるため、この生徒の最終成績は10以下(つまり0)になると思います。プログラムをもう一度実行して、何が起こるか見てみましょう。
出力は次のようになります。
Algorithm predicted class: [1]
Algorithm predicted class: [0]
私たちのモデルは、スペクトルの下限または上限のいずれかの数値に期待することを実行しているように見えます。しかし、数字が反対の場合(例として1と5、または2と3のさまざまな組み合わせを自由に試してみてください)、または真ん中にある場合は苦労します。また、エポックのデータから、エラーは減少しますが、非常に高いままであることがわかります(20%半ば)。これは、アルコール消費量とコースの成績との間に関係がない可能性があることを意味します。 Kaggleの元のデータセットを試してみることをお勧めします。コースの結果を予測するために使用できる他の独立変数はありますか?
このすべてを機能させるために、内部で発生する多くの複雑さ(主に数学に関して)があります。興味があり、詳細を知りたい場合は、FANNのドキュメントを確認するか、ruby-fannのソースコードを確認することを強くお勧めします。 宝石。また、Netflixの「AlphaGo」ドキュメンタリーをチェックすることをお勧めします。これを楽しむのに多くの技術的知識は必要ありません。ディープラーニングがコンピューターの達成可能性の限界を押し上げている実例を示しています。
カーツワイルは彼の予測で正しいものになるのでしょうか?時間だけが教えてくれます!
-
Ruby2.6の9つの新機能
Rubyの新しいバージョンには、新しい機能とパフォーマンスの改善が含まれています。 変更についていきますか? 見てみましょう! 無限の範囲 Ruby 2.5以前のバージョンは、すでに1つの形式の無限範囲をサポートしています( Float ::INFINITY を使用) )、しかしRuby2.6はこれを次のレベルに引き上げます。 新しい無限の範囲 次のようになります: (1..) これは、(1..10)のような終了値がないため、通常の範囲とは異なります。 。 使用例 : [a, b, c].zip(1..) # [[a, 1], [b, 2], [c, 3]] [1,2,3,
-
カプセル ネットワークは従来のニューラル ネットワークに取って代わるか?
過去数年間の人工知能の成功は、ディープ ニューラル ネットワークに直接起因する可能性があります。画像認識からスマート サーモスタット、自動運転車まで、AI はスマートフォンを含むあらゆるものにアクセスできます。それが、ユニバーサルニューラルネットがどのようになったかです。ただし、このシステムの重要な原則の一部が、AI が直面する主要な問題を克服できない可能性があるという懸念が高まっています。これは、「従来の」ニューラル ネットワークが市場から姿を消し、最先端のもの、つまり「カプセル」ニューラル ネットワークに取って代わられる可能性があることを意味します。 従来型/人工ニューラル ネットワークと