MongoDBのヒント:パート1
Tricoreが最初に公開したもの:2017年8月2日
MongoDBの使用を開始するのは簡単ですが、アプリケーションを構築するときに、より複雑な問題が発生します。次のようなことを不思議に思うかもしれません:
- レプリカセット内のレプリカメンバーを再同期するにはどうすればよいですか?
- クラッシュ後にMongoDBを回復するにはどうすればよいですか?
- ファイルの保存と取得にMongoDBのGridFS仕様を使用する必要があるのはいつですか?
- 破損したデータを修正するにはどうすればよいですか?
このブログ投稿では、MongoDBを使用しているときにこれらの状況に対処するためのヒントをいくつか紹介しています。
ヒント1:データを回復するために修復コマンドに依存しないでください
データベースがクラッシュし、–journalを実行していない場合 フラグを立てて、そのサーバーのデータを使用しないでください。
MongoDBのrepair コマンドは、検出できるすべてのドキュメントを調べて、そのドキュメントのクリーンコピーを作成します。ただし、このプロセスには時間がかかり、大量のディスクスペース(現在使用されているのと同じ量のスペース)を使用し、破損したレコードをスキップすることに注意してください。 MongoDBのレプリケーションプロセスでは破損したデータを修正できないため、再同期する前に、破損している可能性のあるデータを必ず消去する必要があります。
ヒント2:レプリカセットのメンバーを再同期する
レプリカセットのメンバーを再同期するには、少なくとも1つのセカンダリメンバーと1つのプライマリメンバーが稼働していることを確認してください。次に、Oracleという名前のユーザーとしてログインしていることを確認し、MongoDBサービスを停止します。
MongoDBという名前のユーザーとしてログインし、バックアップフォルダー内のすべてのデータファイルを移動して、問題が発生した場合に復元できるようにします。古いファイルがバックアップフォルダにある場合は、それらを削除できます。データファイルの場所がわからない場合は、/etc/mongod.confをご覧ください。 .Oracleという名前のユーザーとして、MongoDBサービスを開始します。
データベースにログインして検証します。メンバーがレプリカセットで同期されるまで、データベースにアクセスするために認証する必要はありません。
レプリケーションプロセスが完了すると、ステータスがSTARTUP2から変更されます。 SECONDARYへ 。
ヒント3:小さなバイナリデータにはGridFSを使用しないでください
MongoDBは、GridFS仕様を使用して、大きなファイルを保存および取得します。つまり、GridFSは、大きなバイナリオブジェクトをデータベースに格納する前に分割します。 GridFSには2つのクエリが必要です。1つはファイルのメタデータをフェッチするためのもので、もう1つはそのコンテンツをフェッチするためのものです。したがって、GridFSを使用して小さなファイルを保存すると、アプリケーションが実行する必要のあるクエリの数が2倍になります。
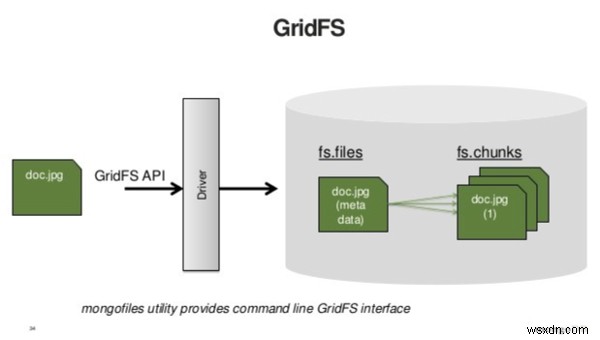
出典:https://www.slideshare.net
GridFSはビッグデータを保存するように設計されています。つまり、データが大きすぎて1つのドキュメントに収まりません。経験則として、クライアントにロードするには大きすぎるものは、サーバーに一度にロードしたいものではない可能性があります。別の方法はストリーミングです。クライアントにストリーミングする予定のあるものはすべて、GridFSの候補として適しています。
ヒント4:ディスクアクセスを最小化する
開発者は、RAMからのデータへのアクセスが高速で、ディスクからのデータへのアクセスが遅いことを知っています。
ディスクアクセスの数を最小限に抑えることが優れた最適化手法であることはご存知かもしれませんが、このタスクを実行する方法がわからない場合があります。
1つの方法は、ソリッドステートドライブ(SSD)を使用することです。 SSDは、従来のハードディスクドライブ(HDD)よりもはるかに高速に多くのタスクを実行します。また、MongoDBでも非常にうまく機能します。一方、それらは多くの場合、より小さく、より高価です。
次の画像は、SSDとHDDを比較しています。

出典:https://www.serverintellect.com
ディスクアクセスの数を減らすもう1つの方法は、RAMを追加することです。ただし、最終的にRAMがデータのサイズに対応できなくなるため、このアプローチではこれまでのところしか使用できません。
問題は、テラバイトまたはペタバイトのデータをディスクに保存し、頻繁に要求されるデータにメモリ内でアクセスするアプリケーションをプログラムし、データをディスクからメモリにできるだけ頻繁に移動しないようにする方法です。
すべてのデータにリアルタイムでランダムにアクセスする場合、答えは大量のRAMが必要になるということです。ただし、ほとんどのアプリケーションはこのようには機能しません。最近のデータは古いデータよりも頻繁にアクセスされ、特定のユーザーは他のユーザーよりもアクティブであり、特定の地域には他の地域よりも多くの顧客がいます。この説明に適合するアプリケーションは、特定のドキュメントをメモリに保持するように設計できます。非常にまれにディスクにアクセスします。
ヒント5:データベースがクラッシュした後、MongoDBを通常どおり起動します
ジャーナリングを実行していて、システムが回復可能な方法でクラッシュした場合は、データベースを正常に再起動できます。すべての通常のオプション、特に-- dbpathを使用していることを確認してください (ジャーナルファイルを見つけることができるように)および--journal 。
MongoDBは、接続の受け入れを開始する前に、データを自動的に修正します。このプロセスは、大規模なデータセットの場合は数分かかる場合がありますが、大規模なデータセットの修復を実行するのに通常かかる時間よりもはるかに短い時間です。
ジャーナルファイルはjournalに保存されます ディレクトリ。これらのファイルは削除しないでください。
ヒント6:修復コマンドを使用してデータベースを圧縮します
修復コマンドは基本的にmongodumpを実行します 次に、mongorestore 、データのクリーンコピーを作成します。その過程で、データファイルの空の「穴」も削除されます。
修復コマンドは操作をブロックし、データベースが現在実行しているディスク容量の2倍を必要とします。ただし、別のマシンがある場合は、mongodumpを使用して同じプロセスを手動で実行できます。 およびmongorestore 。
プロセスを手動で完了するには、次の手順を使用します。
-
Hyd1マシンと
fsyncをステップダウンします およびlock:rs.stepDown() db.runCommand({fsync : 1, lock : 1}) -
ファイルをHyd2にダンプします:
Hyd2$ mongodump --host Hyd1 -
Hyd1でデータファイルのコピーを作成して、バックアップとして保持できるようにします。次に、元のデータファイルを削除し、emptydataを使用してHyd1を再起動します。
-
Hyd2から復元します。データファイルを復元するには、次のコマンドを入力します。
Hyd2$ mongorestore --host Hyd1 --port 10000 # specify port if it's not 27017
これらの変更により、MongoDBのパフォーマンスが大幅に向上しました。 MongoDBの使用を計画している場合は、この記事をブックマークしてから、この記事に戻って、次に新しいプロジェクトを開始するときに各ヒントを確認することをお勧めします。
この2部構成のシリーズのパート2では、大企業が有用なMongoDB機能を適切に設計、最適化、および実装するのに役立つヒントをいくつか紹介します。
[フィードバック]タブを使用して、コメントを書き込んだり、質問したりします。
-
MongoDBを使用したスケーリング:シャーディングインフラストラクチャのセットアップ
最近のブログ投稿で、MongoDBをスケーリングする必要がある場合について説明しました。この投稿では、MongoDBをスケーリングする方法に焦点を当てています。 MongoDBバージョン3.0では、デフォルトのストレージエンジンとしてWiredTigerが導入されました。それ以来、MongoDBは、スケーラビリティに関して2つのアプローチを提供できるようになりました。 Mongoは、水平方向だけでなく垂直方向にも拡張できるようになりました。どちらのアプローチも詳細を確認する必要があります。 垂直方向のスケーリング 垂直方向にスケーリングすると、CPUの数や種類、RAMやディスク容
-
MongoDBのスペース使用量を理解する
MongoDBを初めて使用する方にとって、MongoDBのスペース使用量は非常に混乱しているように思われるかもしれません。この記事では、MongoDBがスペースを割り当てる方法と、ObjectRocketダッシュボードのスペース使用量情報を解釈して、インスタンスを圧縮する必要がある場合や、インスタンスで使用可能なスペースを増やすためにシャードを追加する必要がある場合を判断する方法について説明します。 まず、単一の5GBシャードで構成される新しいMediumインスタンスから始めましょう。このインスタンスに「ocean」という名前のデータベースのテストデータを入力します。テストデータを追加し、い