Hadoopエコシステムの基本:パート2
Tricoreが最初に公開したもの:2017年7月11日
Apache™Hadoop®に関するこの2部構成のシリーズのパート1では、HadoopecosystemとHadoopフレームワークを紹介しました。パート2では、クエリ、外部統合、データ交換、調整、管理など、Hadoopフレームワークのコアコンポーネントについて説明します。また、Hadoopクラスターを監視するモジュールも紹介します。
このシリーズのパート1では、スクリプトツールとしてApachePig™を紹介しました。PigLatinで記述されたPigは、実行可能なMapReduceジョブに変換されます。パート1で詳しく学ぶことができるいくつかの利点があります。
ただし、一部の開発者は依然としてSQLを好みます。知っていることを使いたい場合は、代わりにHadoopでSQLを使用できます。
ApacheHive™は、大量のデータを管理および整理する分散データウェアハウスです。このウェアハウスは、HadoopDistributed File System(HDFS™)の上に構築されています。 Hiveクエリ言語であるHiveQLは、SQLセマンティクスに基づいています。ランタイムエンジンは、HiveQLをデータをクエリするMapReduceジョブに変換します。
Hiveは次の機能を提供します:
-
大量の生データを格納するためのスキーマ化されたデータストア。
-
HDFSの生データに対して分析とクエリを実行するためのSQLのような環境。
-
外部のリレーショナルデータベース管理システム(RDBMS)アプリケーションとの統合。
次の画像は、Hadoopエコシステムのアーキテクチャを視覚化したものです。
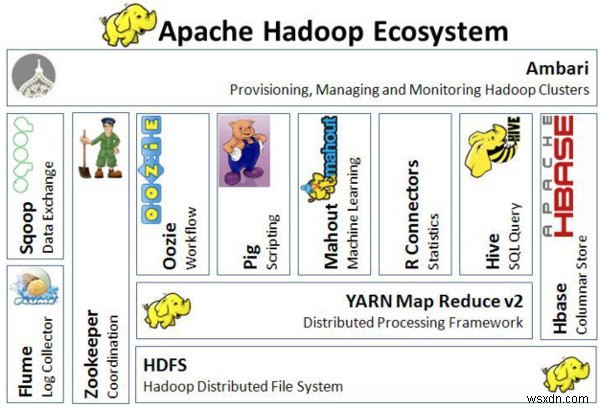 Hadoopエコシステムのアーキテクチャ
Hadoopエコシステムのアーキテクチャ ApacheFlume™は、大量のログデータを効率的に収集、集約、およびHDFSに移動するための、分散型で信頼性が高く、利用可能なサービスです。 Flumeは、フォールトトレラントでフェイルオーバーリカバリに対応したストリーミングデータフローアーキテクチャを使用して、大量のイベントデータを転送します。
Flumeは次の機能も提供します:
-
ネットワークトラフィック、ログ、電子メールメッセージなどの大量のイベントデータを転送します。
-
複数のソースからHDFSにデータをストリーミングします。
-
Hadoopアプリケーションへの信頼性の高いリアルタイムデータストリーミングを保証します。
ApacheSqoop™は、Hadoopと、リレーショナルデータベースやエンタープライズデータウェアハウスなどの外部データストアとの間でバルクデータを効率的に転送するように設計されています。 Sqoopは、TeradataDatabase、IBM®Netezza、Oracle®Database、MySQL™、PostgreSQL®などのリレーショナルデータベースと連携します。 Sqoopは、ビッグデータを収集または分析するほとんどの企業で広く使用されています。
Sqoopは次の機能を提供します:
-
データベースによっては、インポートされたデータのスキーマを記述するプロセスのほとんどを自動化できます。
-
MapReduceフレームワークを使用して、データをインポートおよびエクスポートします。これにより、Sqoopはパラレルメカニズムとフォールトトレランスを提供できます。
-
すべての主要なRDBMSデータベースにコネクタを提供します。
-
フルロードとインクリメンタルロード、データの並列エクスポートとインポート、およびデータ圧縮をサポートします。
-
Kerberosセキュリティ統合をサポートします。
ApacheZookeeper™は、クラスター間の同期を可能にする分散アプリケーションの調整サービスです。分散アプリケーションがデータを保存および取得できる一元化されたリポジトリを提供します。
Zookeeperは、クラスター内のジョブを管理するために使用される管理用Hadoopツールです。一部の開発者は、あるノードのデータへの変更が他のノードに伝達されるため、このツールを「ウォッチガード」と呼んでいます。
Hadoopクラスターのプロビジョニング、管理、および監視
ApacheAmbari™は、Apache Hadoopクラスターをプロビジョニング、管理、および監視するためのWebベースのツールです。ツールをインストールし、管理、構成、および監視タスクを実行するための、非常にシンプルでありながら高度にインタラクティブなユーザーインターフェイスを備えています。 Ambariは、ヒートマップなどのクラスターヘルスに関する情報を表示するためのダッシュボードを提供します。また、MapReduce、Pig、およびHiveアプリケーションを機能と一緒に表示できるため、それらのパフォーマンス特性を簡単に診断できます。
Ambariは、次の機能も提供します。
-
ノードを使用したマスターサービスのマッピング。
-
インストールするサービスを選択する機能。
-
シンプルなカスタムスタックの選択。
-
よりクリーンなインターフェース。
-
合理化されたインストール、監視、および管理。
Hadoopは、大量のデータを保存および分析したい企業にとって非常に効果的なソリューションです。これは、分散システムでのデータ管理のための非常に人気のあるツールです。オープンソースであるため、企業は自由に利用できます。 Hadoopの詳細については、ApacheSoftwareFoundationのWebサイトにある公式ドキュメントを参照してください。
Hadoopを使用したことがありますか? [フィードバック]タブを使用して、コメントを書き込んだり、質問したりします。
-
ビッグ データに最適なプログラミング言語 – パート 1
ビッグデータに関する前回のブログでは、機能アーキテクチャの 8 つのレイヤーであるデータ統合ツールについて説明しました。このブログでは、機能層アーキテクチャの第 9 層を形成するデータ言語をリストします。 現在、ビッグ データ プロジェクトは、大小を問わずすべての業界で一般的になっています。すべての業界が、ビッグ データが提供するすべての洞察を活用しようとしています。どんなに高度な GUI ベースのソフトウェアを開発しても、コンピュータ プログラミングはすべての中核です。ツールの種類に関する以前のブログが、貴社のビッグ データ オーガニゼーションの計画に役立つことを願っています。しかし、レイヤ
-
ビッグ データに最適なプログラミング言語 – パート 2
データ サイエンスに最適なプログラミング言語に関するブログの最初の部分では、7 つの言語について説明しました。それらには、ビッグデータを扱う最大の人々によって使用されている言語が含まれていました. このブログでは、最初の部分のプログラミング言語に関する新規参入者で構成されるリストの残りの半分をリストしています。その中には、Java、Hadoop、R、SQL と同様に人気を博したものもあれば、それらが提供する優れた機能により、市場で注目すべき地位を築いたものもあります。 データ サイエンス用プログラミング言語のリスト: 1.パイソン – Python は、ビッグ データに必要な大規模で複雑なデ