Redis リストと TypeScript を使用してカスタム メッセージ キューを構築する
独自のメッセージ キューを作成しようとして困難に直面したことがありますか?そうであれば、あなたは一人ではありません。このチュートリアルでは、Redis リストを使用してメッセージ キューを最初から構築します。Redis でメッセージ キューを構築するには、ストリーム、リスト、パブリッシュ/サブスクライブなどいくつかの方法がありますが、最も単純で直接的なアプローチであるリストに焦点を当てます。この実践的なガイドを詳しく掘り下げていきますので、ぜひご参加ください。
使用するもの
- アップスタッシュ
- 両手
必要なもの
- パン
- 両手
Upstash Redis のセットアップ
まず、Redis インスタンスを設定しましょう。これを行うには、Upstash に移動し、データベースの作成 をクリックします。 その後、下にスクロールして、クライアントとの接続に使用する接続文字列を見つけます。ここでは詳細には触れませんが、基本的にはこれで始める必要があります。
接続文字列の例:
redis://XXXXe@social-XXX-39281.upstash.io:39281プロジェクトのキックオフ
Bun を使用して TypeScript プロジェクトを開始しましょう。この選択は、Node よりも速いという理由だけではなく、セットアップがはるかに簡単であるという理由でもあります。そして、はい、驚くほど速いです! 🚀
mkdir upstash-mq
cd upstash-mq
bun init
> package name (upstash-mq-tutorial): upstash-mq
> entry point (index.ts):
> Done!
bun add ioredisプロジェクトの構造
┣ 📂src
┃ ┣ 📂lua-scripts
┃ ┃ ┣ 📜add-job.lua
┃ ┃ ┗ 📜remove-job.lua
┃ ┣ 📜index.ts
┃ ┣ 📜job.ts
┃ ┣ 📜queue.ts
┃ ┗ 📜utils.ts
┣ 📜.env
┣ 📜.gitignore
┣ 📜README.md
┣ 📜bun.lockb
┣ 📜index.ts
┣ 📜package.json
┗ 📜tsconfig.json
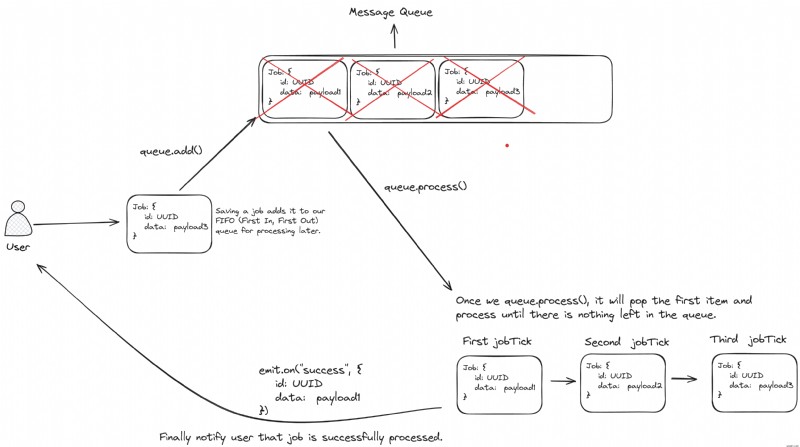
Queue の視覚的表現 次のようになります:
仕事
私たちの Job クラスには、いくつかの重要なことが必要です。まず、各ジョブのステータスを追跡する必要があります。これは、ジョブを処理するか、再試行するか、すでに終了している場合は別の場所に移動するかを決定するのに役立ちます。各ジョブには ID といくつかのデータもあり、優れたユーザー エクスペリエンスを提供できるように汎用性が必要です。最後に、管理を容易にするために、各ジョブをキューにリンクし、キュー名を含める必要があります。
Job のバックボーンは次のとおりです。 クラス:
type OwnerQueue = {
redis: Redis;
queueName: string;
};
export type JobStatuses =
| "created"
| "waiting"
| "active"
| "succeeded"
| "failed";
export class Job<T> {
id: string;
status: JobStatuses;
config: OwnerQueue;
data: T;
constructor(ownerConfig: OwnerQueue, data: T, jobId = randomUUID()) {
this.id = jobId;
this.status = "created";
this.data = data;
this.config = ownerConfig;
}
}
data を作成するには 一般的なものなので、最初に Job を作成する必要があります。 それ自体がジェネリックです。残りは簡単に続きます。Job ごとに個別の Redis インスタンスを作成できます。 要素ですが、これを管理するのは複雑になります。
幸いなことに、私たちのアプローチではキュー内で Redis インスタンスを簡単に構成でき、必要に応じてこのインスタンスを渡すだけで済みます。同じ原則が queueName にも適用されます 。ジョブをキューに保存するために頻繁に使用するため、ジョブは親キューを認識する必要があります。ジョブをキューに保存できるようにするには、Redis と対話するための Lua スクリプトといくつかのユーティリティという 2 つのものが必要です。
まずユーティリティを作成しましょう:
import { JobStatuses } from "./job";
const MQ_PREFIX = "UpstashMQ";
export const formatMessageQueueKey = (queueName: string, key: string) => {
return `${MQ_PREFIX}:${queueName}:${key}`;
};
export const convertToJSONString = <T>(
data: T,
status: JobStatuses,
): string => {
return JSON.stringify({
data,
status,
});
};
Redis を使用するたびにキュー名を手動で作成するのは理想的ではないため、formatMessageQueueKey というユーティリティを作成しました。 このユーティリティは単に文字列を連結するだけです。さらに、Redis に保存するためにデータをシリアル化する必要があります。単に JS オブジェクトをデータ ソースとして渡すことはできません。最初に文字列に変換する必要があります。データが汎用であることを考慮して、汎用関数 convertToJSONString を実装しました。 、この目的のために。
ここで、最初の lua スクリプトを追加しましょう。
add-job.lua
--[[
key 1 -> [prefix]:name:jobs
key 2 -> [prefix]:name:waiting
arg 1 -> job id
arg 2 -> job data
]]
local jobId = ARGV[1]
local payload = ARGV[2]
if redis.call("hexists", KEYS[1], jobId) == 1 then return nil end
redis.call("hset", KEYS[1], jobId, payload)
redis.call("lpush", KEYS[2], jobId)
return jobId次のように、これらの呼び出しを Redis インスタンスで個別に実行できます。
redis.hexists(jobId)redis.hset(jobId,payload)redis.lpush(jobId,payload)
ただし、このアプローチでは 3 つの別々の呼び出しが必要になります。 Redis サーバーへの往復を最小限に抑えるために、プロセス全体を 1 つの呼び出しに統合することを目指しています。
save() を追加しましょう メソッド
private createQueueKey(key: string) {
return formatMessageQueueKey(this.config.queueName, key);
}
async save(): Promise<string | null> {
const addJobToQueueScript = await Bun.file("./src/lua-scripts/add-job.lua").text();
const resJobId = (await this.config.redis.eval(
addJobToQueueScript,
2,
this.createQueueKey("jobs"),
this.createQueueKey("waiting"),
this.id,
convertToJSONString(this.data, this.status)
)) as string | null;
if (resJobId) {
this.id = resJobId;
return resJobId;
}
return null;
}
コードは単純ですが、さらに詳しく説明します。 Lua スクリプトを作成した後、redis.eval を使用して呼び出します。 , Lua スクリプトの実行に必要です。 redis.eval のパラメータ は次のとおりです。
- 最初のパラメータにはスクリプトが必要です。
- 2 番目のパラメータは引数の数を指定します。
- 3 番目と 4 番目のパラメータはキー用です。
- 最後に、実際の引数を渡します。
Job を完了する前に クラスには、将来のためにさらにいくつかのメソッドを追加しましょう。
fromId = async <T>(jobId: string): Promise<Job<T> | null> => {
const jobData = await this.config.redis.hget(this.createQueueKey("jobs"), jobId);
if (jobData) {
return this.fromData<T>(jobId, jobData);
}
return null;
};
private fromData = <T>(jobId: string, stringifiedJobData: string): Job<T> => {
const parsedData = JSON.parse(stringifiedJobData) as Job<T>;
const job = new Job<T>(this.config, parsedData.data, jobId);
job.status = parsedData.status;
return job;
};
現時点ではこれらの機能は必要ないかもしれませんが、将来ジョブの処理を開始するときに重要になります。この時点では、ジョブの ID (jobId) のみが存在します。 、ジョブを最初から再構築する方法が必要になります。これはまさに fromId です。 達成します。 Redis からジョブ データを取得し、ジョブ インスタンスに変換して返します。これにより、後でキューがこのジョブを処理できるようになります。
キューに進む
save() を完了していること パートでは、Queue の詳細を見てみましょう。私たちの目標は次のとおりです。
- 後で再処理が必要になる場合があるため、キューでは成功時または失敗時にデータを保持または削除することを目指しています。
- 私たちは並行性を考慮してキューを設計し、複数のジョブを同時に実行できるようにする予定です。
- 私たちの目標は、データ処理のためにコールバック関数を渡せるようにすることです。この関数は、開発者のエクスペリエンスを向上させるために、ジョブのタイプを推測する必要があります。
Job.save()の呼び出しを有効にする予定です キュー内から、Redis インスタンスとqueueNameを渡すことができます。 .- 最後に、必要に応じてキューを破棄し、キューからジョブを削除できるようにしたいと考えています。
キューの定義から始めましょう
export type QueueConfig = {
redis: Redis;
queueName: string;
keepOnSuccess?: boolean;
keepOnFailure?: boolean;
};
export class Queue extends EventEmitter {
config: QueueConfig;
concurrency = 0;
worker: any;
running = 0;
queued = 0;
constructor(config: QueueConfig) {
super();
this.config = {
redis: config.redis,
queueName: config.queueName,
keepOnFailure: config.keepOnFailure ?? true,
keepOnSuccess: config.keepOnSuccess ?? true,
};
}
createQueueKey(key: string) {
return formatMessageQueueKey(this.config.queueName, key);
}
}Queue クラスには、キュー名、Redis インスタンス、データの保持または削除の設定などの外部情報を受け入れるための構成が含まれています。ユーザーが好む Redis 実装は歓迎しますが、特に Upstash を優先します 😌。この柔軟性により、ユーザーはキューを既存のシステムに簡単に統合できます。
また、私たちのクラスは Event Emitter を拡張して、何かが起こったときに通知します。
初期化の例を次に示します。
const queue = new Queue({
redis: new Redis(process.env.UPSTASH_REDIS_URL),
queueName: "upstash-rocks",
keepOnFailure: true,
keepOnSuccess: true,
});追加
async add<T>(payload: T) {
return new Job<T>(this.config, payload).save();
}私たちのジョブは、親キューの構成の詳細と、Redis に保存されるデータであるペイロードを取得します。あとはそれを保存するだけです。
これで、次のことができるようになります。
const queue = new Queue({
redis: new Redis(process.env.UPSTASH_REDIS_URL!),
queueName: "mytest-queue",
keepOnFailure: true,
keepOnSuccess: true,
});
const payload = {
upstash: "best-redis-ever",
};
await queue.add(payload);ここで、それらを処理する方法が必要です。
処理中
これはキューの実装で最も難しい部分です。ユーザーには、同時プロセスの数を指定し、ワーカー、つまりジョブの種類を推測するジョブを処理するコールバック関数を提供するよう求めています。 さらに、現在実行中でキューに入れられているジョブの数を追跡し、キューから次のジョブを安全に選択できるようにするメカニズムも必要です。
async process<TJobPayload>(
worker: (job: TJobPayload) => void,
concurrency: number
): Promise<void> {
this.concurrency = concurrency;
this.worker = worker;
this.running = 0;
this.queued = 1;
this.jobTick();
}
汎用の TJobPayload を受け入れる主な目的 ユーザーの開発者エクスペリエンスを向上させることを目的としています。ユーザーがキューを使用するときにインテリセンスの恩恵を受けられるようにすることを目指しています。ユーザーは、{hello: "world"} のようなデータを保存していることに気づいています。 ジョブでは実行されますが、TypeScript には正確なインテリセンスを提供するための支援が必要です。このため、開発者エクスペリエンスを向上させるために、TypeScript に通知して推論を強制するために、このメカニズムを導入しています。
jobTick() に進む前に 、プロセスを注意深く検討してみましょう:
- キューは FIFO (先入れ先出し) ベースで動作するため、キューの右側からジョブをポップすることから始める必要があります。
- 次に、このジョブに対してワーカー関数を実行します。
- ジョブが完了したら、結果をユーザーに送信します。
- 最後に、
jobTick()を呼び出します。 次のジョブを処理するために再度実行します。
したがって、jobTick() はこれら 3 つの重要な部分で構成されます。」
private jobTick() {
this.getNextJob()
.then(async (jobId) => {
this.running += 1;
this.queued -= 1;
if (this.running + this.queued < this.concurrency) {
this.queued += 1;
setImmediate(this.jobTick);
}
if (!jobId) {
return;
}
const jobCreatedById = await new Job(this.config, null).fromId(jobId);
if (jobCreatedById) {
await this.executeJob(jobCreatedById);
} else {
console.error(`Job not found with ID: ${jobId}`);
}
})
.catch((error) => {
console.error("Error in jobTick:", error);
})
.finally(() => {
setImmediate(() => this.jobTick());
});
}
機能ごとに説明していきたいと思います。 getNextJob() から始めましょう
private async getNextJob() {
try {
const jobId = await this.config.redis.brpoplpush(
this.createQueueKey("waiting"),
this.createQueueKey("active"),
0
);
return jobId;
} catch (error) {
console.error("Error fetching the next job:", error);
throw error;
}
}
ここでは単に Redis を呼び出しているだけですが、戦略的なアプローチを採用しています。lpush と組み合わせたブロッキング呼び出しを使用しています。 往復回数を最小限に抑えるためです。ブロッキング呼び出しの使用は意図的です。他のワーカーが同じジョブを同時に処理できないようにして、競合状態を回避したいと考えています。さらに、ジョブを「待機中」状態から「アクティブ」状態に移行し、プロセスの次のステップに向けて効果的に準備します。
this.getNextJob().then(async (jobId) => {
this.running += 1;
this.queued -= 1;
if (this.running + this.queued < this.concurrency) {
this.queued += 1;
setImmediate(this.jobTick);
}
if (!jobId) {
return;
}
const jobCreatedById = await new Job(this.config, null).fromId(jobId);
if (jobCreatedById) {
await this.executeJob(jobCreatedById);
} else {
console.error(`Job not found with ID: ${jobId}`);
}
});
jobId が完成しました。 、実行中のジョブの数を 1 つ増やし、キューに入れられた数を 1 つ減らします。また、同時実行制限を尊重しながら、できるだけ多くの新しいジョブを開始しようとします。
if (this.running + this.queued < this.concurrency) {
this.queued += 1;
setImmediate(this.jobTick);
}
すべてがうまくいけば、Job の構築に進みます。 fromId を使用 ID によるジョブの再構築に成功したら、ワーカー関数を使用したジョブの実行に進みます。
executeJob に進みましょう
private async executeJob<TJobPayload>(jobCreatedById: Job<TJobPayload>) {
let hasError = false;
try {
await this.worker(jobCreatedById.data);
this.running -= 1;
this.queued += 1;
} catch (error) {
hasError = true;
} finally {
const [jobStatus, job] = await this.finishJob<TJobPayload>(jobCreatedById, hasError);
this.emit(jobStatus, job.id);
return;
}
}
ジョブのデータを取得したので、このデータを worker に渡します。 。正常に実行されると、キューに入れられたジョブの数が 1 つ増え、実行中のジョブの数が 1 つ減ります。このステップは非常に重要です。正しく処理されないと、新しいジョブを同時に起動する能力に影響を与える可能性があります。ワーカーの実行中にエラーが発生した場合は、単に hasError を切り替えるだけです。 旗。最後に、finishJob を呼び出します。 jobCreatedById を使用して と hasError jobId でフラグを立ててステータスを出力します .
補足:ユーザーは、このように発行された更新をリッスンできるようになりました。
queue.on("succeeded", (jobId) => console.log("Succeeded jobId", jobId));
finishJob に進みましょう
private async finishJob<TJobPayload>(
job: Job<TJobPayload>,
hasFailed?: boolean
): Promise<[JobStatuses, Job<TJobPayload>]> {
const multi = this.config.redis.multi();
multi.lrem(this.createQueueKey("active"), 0, job.id);
if (hasFailed) {
if (this.config.keepOnFailure) {
multi.hset(this.createQueueKey("jobs"), job.id, convertToJSONString(job.data, job.status));
multi.sadd(this.createQueueKey("failed"), job.id);
} else {
multi.hdel(this.createQueueKey("jobs"), job.id);
}
job.status = "failed";
} else {
if (this.config.keepOnSuccess) {
multi.hset(this.createQueueKey("jobs"), job.id, convertToJSONString(job.data, job.status));
multi.sadd(this.createQueueKey("succeeded"), job.id);
} else {
multi.hdel(this.createQueueKey("jobs"), job.id);
}
job.status = "succeeded";
}
await multi.exec();
return [job.status, job];
}
ここで重要な点は、multi() の使用です。 私たちの目的は常に往復を最小限に抑えることであるため、multi を使用します。 , Redis は、exec() を呼び出すまで実行を延期します。 ユーザーが keepOnFailure を設定した場合 と keepOnSuccess データを保存するために、2 つのセットを作成します。1 つはジョブのデータで、もう 1 つはこのデータにアクセスするためのジョブ ID のリストです。このアプローチは、成功シナリオと失敗シナリオの両方に適用されます。当然、それに応じてジョブのステータスを調整します。最後に、exec を使用して multi コマンドを実行します。 イベント発行の目的で、ジョブのステータスとジョブ自体を返します。
最後に、残りの 2 つの方法がありますが、これらは私たちがすでによく知っている概念を利用しているため、詳しくは説明しません。
async removeJob(jobId: string) {
const addJobToQueueScript = await Bun.file("./src/lua-scripts/remove-job.lua").text();
return await this.config.redis.eval(
addJobToQueueScript,
5,
this.createQueueKey("succeeded"),
this.createQueueKey("failed"),
this.createQueueKey("waiting"),
this.createQueueKey("active"),
this.createQueueKey("jobs"),
jobId
);
}
async destroy() {
const args = ["id", "jobs", "waiting", "active", "succeeded", "failed"].map((key) =>
this.createQueueKey(key)
);
const res = await this.config.redis.del(...args);
return res;
}ジョブ.lua を削除
--[[
key 1 -> [prefix]:test:succeeded
key 2 -> [prefix]:test:failed
key 3 -> [prefix]:test:waiting
key 4 -> [prefix]:test:active
key 5 -> [prefix]:test:jobs
arg 1 -> jobId
]]
local jobId = ARGV[1]
if (redis.call("sismember", KEYS[1], jobId) + redis.call("sismember", KEYS[2], jobId)) == 0 then
redis.call("lrem", KEYS[3], 0, jobId)
redis.call("lrem", KEYS[4], 0, jobId)
end
redis.call("srem", KEYS[1], jobId)
redis.call("srem", KEYS[2], jobId)
redis.call("hdel", KEYS[5], jobId)
destroy() 1 つはキュー全体を完全に消去すること、もう 1 つはキューから特定のジョブを削除することです。
実際の動作を見てみましょう
import { sleep } from "bun";
import Redis from "ioredis";
import { Queue } from "./queue";
type Payload = {
id: number;
data: string;
};
const queue = new Queue({
redis: new Redis(process.env.UPSTASH_REDIS_URL),
queueName: "mytest-queue",
});
async function main() {
await generateQueueItems(queue, 20);
console.log("Sleep starting for 5 sec");
await sleep(5000);
queue.on("succeeded", (jobId) => console.log("Succeeded jobId", jobId));
await queue.process<Payload>((job) => {
console.log("Processing job:", job.data);
sleep(1000);
}, 3);
}
main();
async function generateQueueItems(queue: Queue, itemCount: number) {
for (let i = 0; i < itemCount; i++) {
const payload = {
id: i,
data: `dummy-data-${i}`,
// Add more properties as needed for your testing
};
const jobId = await queue.add(payload);
console.log(`Added item ${i} with jobId: ${jobId}`);
}
}ボーナス チャレンジ
- Redis アクセスとワーカー プロセスの両方に指数バックオフを使用した再試行ロジックを実装する
- 「少なくとも 1 回」の保証メカニズムを開発する
- パフォーマンスを向上させるために、Service Worker でワーカーを実行するようにしてください
- スケジュールされたジョブを追加する
まとめ
何かを学ぶための最良の方法は、それを構築することですが、さらに良い方法は、Upstash Redis を使用して学習することです。揺れ続けてください。
🔗 プロジェクトの Github アドレス
-
Redis HSTRLEN –ハッシュに含まれるフィールド値の長さを取得する方法
このチュートリアルでは、キーに格納されているハッシュ値に含まれるフィールドの値の長さを取得する方法について学習します。このために、Redis HSTRLENを使用します コマンド。 HSTRLENコマンド このコマンドは、指定されたキーに格納されているハッシュ値のフィールドに関連付けられている値の長さ(文字数)を返します。キーが存在しない場合、またはキーは存在するがハッシュ値に指定されたフィールドが含まれていない場合はOが返され、キーは存在するがキーに格納されている値がハッシュデータ型ではない場合はエラーが返されます。 RedisHSTRLENコマンドの構文は次のとおりです。- 構文:
-
AWSChaliceとUpstashRedisを使用したサーバーレスバースデーSlackbot
毎年恒例のイベントのリマインダーを作成して、それらの特別な日付を忘れたり見逃したりしないようにするのが最善の場合もあります。 あなたとあなたのチーム/友達がSlackを使用している場合は、slackbotを介してこれらのリマインダーを自動化することをお勧めします。 そうしている間、slackbotをメンテナンスの少ないものにしたい場合は、ソースとの同時対話にはサーバーレステクノロジーを使用するのが最適な場合があり、水平方向のスケーラビリティも可能になります。 私たちが構築しているもの イベントリマインダーSlackbotを構築しています Python、AWS Chalice、AWS La