Redis キャッシュでグローバル データベースのパフォーマンスを高速化
ソフトウェア アプリケーションは、顧客のニーズを満たすことができてこそ価値があります。顧客のニーズを考えるとき、私たちが最初に直面する要求は、アプリケーションの速度とデータの信頼性です。ただし、アプリケーションが世界的に成長し拡大するにつれて、クエリ量の増加、レイテンシの増加、地理的に分散したユーザー ベースにより、SQL データベースがパフォーマンスのボトルネックになることがよくあります。
アプリケーションが増大したときにこれらの問題に対処するため、キャッシュは、繰り返されるクエリに対するプライマリ データベースの負荷を軽減し、ユーザーがクエリを送信するときの待ち時間を短縮するための最初のソリューションの 1 つです。キャッシュについて話すとき、誰もが同じツールを思い浮かべるのではないでしょうか?そう、それがリディスです。 Redis は、データをキャッシュして負荷を軽減し、アプリケーションを高速化するのに最適なツールです。 Upstash は、グローバルに分散された Redis レプリケーションも提供します。これにより、アプリケーションは通常のキャッシュよりもはるかに高速になります。
このブログでは、Global Redis を SQL データベースと統合する技術的利点を探り、レイテンシとスケーラビリティへの影響について説明し、PostgreSQL および MySQL で Global Redis を使用する実践例を提供します。
キャッシュの利点
まず、キャッシュを使用する必要がある理由を検討してみましょう。
このブログで説明したいキャッシュの主な利点は 2 つあります。1 つはデータベースの負荷の軽減、もう 1 つはユーザーのレイテンシーの軽減です。
データベース負荷の軽減
SQL データベースは構造化データと複雑なクエリの管理に優れていますが、負荷が高い場合にはボトルネックになる可能性があります。製品の詳細、ユーザー プロファイル、頻繁にアクセスする設定など、同じデータに対して大量のクエリを繰り返すと、大量の CPU リソースと I/O リソースが消費されます。これらの結果をキャッシュすることで、データベースにアクセスするクエリの数が大幅に減り、データベースはトランザクション処理や更新などのより重要なタスクに集中できるようになります。
例:
- キャッシュなし:ウェブサイト上の人気のある機能により、毎日何百万もの同一のデータベース クエリが生成され、他の操作のパフォーマンスが低下します。
- キャッシュあり:頻繁にアクセスされるクエリ結果は Redis などの高速キャッシュに保存され、データベースのクエリ率が 90% 以上削減されます。
遅延の削減
データベースの負荷を減らすことは、システムの健全性を維持し、データの信頼性を確保するためでした。キャッシュにより、ユーザーのリクエストとクエリにかかる時間も短縮されます。
アプリケーションがデータベースに対して同じデータを繰り返しクエリすると、データの取得には常に時間がかかります。特に、これらのクエリによってデータベースに大きな負荷がかかる場合、これらすべての遅延がさらに増加する可能性があります。これは、リアルタイムのデータ アクセスを必要とするアプリケーションや大量のクエリを処理するアプリケーションの場合に特に問題となり、わずかな遅延でもパフォーマンスに大きな影響を与える可能性があります。
キャッシュは、頻繁にアクセスされるデータをメモリに保存することでこの問題を解決します。これにより、データベースにクエリを実行するよりもはるかに高速に取得できます。キャッシュにより、繰り返されるリクエストに対するデータベース クエリへの依存性が軽減されるため、ネットワークの移動が最小限に抑えられ、複雑なクエリの実行による計算オーバーヘッドが回避されます。その結果、応答時間が劇的に改善され、アプリケーションは高負荷下や分散環境でもより高速で一貫したパフォーマンスを提供できるようになります。
一般的なキャッシュ戦略
アプリケーションのパフォーマンスの最適化に使用される 2 つの主要なキャッシュ戦略、キャッシュアサイドを理解することも重要です。 そしてライトスルー 。各アプローチには、アプリケーションの要件に応じて、ユースケースとトレードオフがあります。
キャッシュアサイド 最も一般的なキャッシュ手法です。この手法では、アプリケーションは最初にキャッシュにデータがあるかどうかを確認します。データがキャッシュにない場合 (キャッシュミス)、データベースからデータを取得し、将来使用できるようにキャッシュに書き込みます。
以下は、キャッシュ アサイドがどのように機能するかを示す簡単な図です。このブログにアクセスする前に、皆さんもすでにどこかで見たことがあるかもしれません。

このキャッシュの利点は、キャッシュ サイズが最適化され、ユーザーが必要に応じてキャッシュ データが再ロードされることです。一方、欠点は、TTL が経過するとキャッシュが消去された後はデータが利用できなくなることです。その時点で、ユーザーがそのデータをリクエストすると、キャッシュが再ロードされます。この場合、ユーザーはクエリが完了するまで待つ必要があります。ただし、もちろん、次のリクエストでは再びキャッシュからデータを取得できます。
ライトスルーの場合 この戦略では、データベースへのすべての書き込み操作が即座にキャッシュにも書き込まれます。これにより、キャッシュはデータベースからの最新データで常に最新の状態になります。
以下は、ライトスルー キャッシュの簡単な図です。

この戦略により、キャッシュとデータベース間のデータの一貫性が確保され、ユーザーからのリクエストを待たずにデータがすでに使用可能になるため、どのリクエストでも待ち時間が長くなります。ただし、不必要なデータであってもキャッシュにすべてのデータが含まれるという欠点があります。それに加えて、データもキャッシュに書き込まれるため、書き込み操作ごとにレイテンシーが発生します。
グローバル Redis とは何ですか? Global Redis の利点
ここで、SQL データベースのパフォーマンスをさらに向上させる方法を調査しましょう。
待機時間のもう 1 つの原因は、データベースの場所です。ほとんどの場合、プライマリ データベースは特定のリージョンにあります。ただし、データ ストアまでの距離によって生じる遅延を最小限に抑えるために、データは最も近い場所に到達できる必要があります。
この問題は、Upstash が提供するグローバルに分散された Redis を使用することで回避できます。
Global Redis は、複数の地理的場所にデータをレプリケートし、グローバルに分散されたアプリケーションの低レイテンシ アクセスを保証する分散キャッシュ ソリューションです。
グローバル Redis を作成する方法を簡単に見てみましょう。まず、Upstash コンソールにログインします。
ログイン後、ここで Redis データベースを作成できます。 Upstash は、リードレプリカを見つけるための複数の場所を提供します。
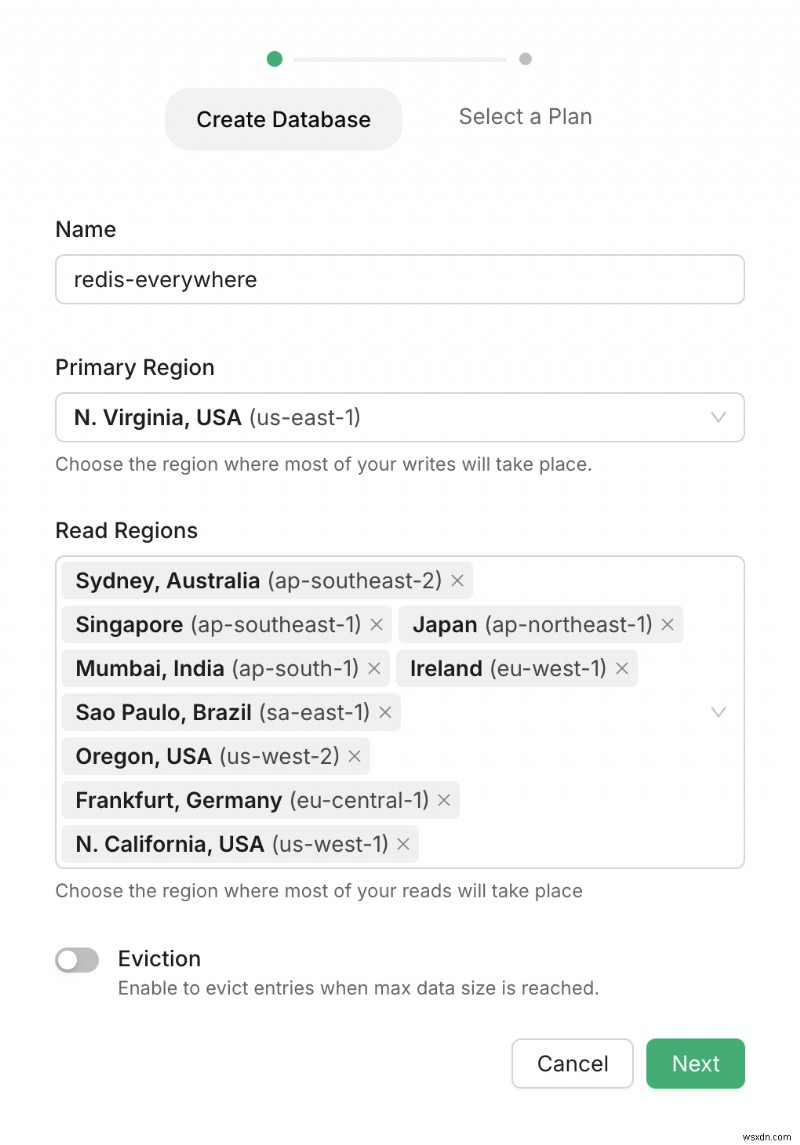
読み取り場所を選択したら、プランを選択して、最後に Redis データベースを作成できます。以上です!
コンソールでは、データベースの作成後にリージョンを追加/削除することもできます。

グローバル Redis データベースは、主に、グローバルに分散されたアプリケーションとエッジで実行されているアプリケーションによって使用されます。
グローバルに分散されたアプリケーションの低遅延
グローバルに分散されたシステムでは、ユーザーと中央データベースまたはキャッシュとの間の物理的な距離により、遅延がボトルネックになることがよくあります。 Global Redis は、地理的に分散した複数のノード間でデータを複製することでこの問題に対処します。
ユーザーがデータをリクエストすると、最も近いキャッシュ ノードがリクエストに対応し、ネットワークの移動時間を大幅に短縮します。このローカライズされたアクセスにより、ユーザーの場所に関係なく、応答時間が短縮され、一貫したユーザー エクスペリエンスが保証されます。
たとえば、ユーザーが東京にいて、データベースがダブリンにある場合、距離によってユーザーへの応答が遅れてしまいます。ヨーロッパに Upstash Redis のリードレプリカがある場合、リクエストは最も近いリードレプリカ (この場合はヨーロッパにあるリードレプリカ) にルーティングできます。
エッジ ランタイムの低レイテンシー データ (Cloudflare ワーカーなど)
エッジ ランタイムは、エンド ユーザーに近いネットワーク エッジでコードを実行するように設計された環境です。エッジ ランタイムは、世界中の複数のエッジの場所にアプリケーション ロジックを分散します。このアーキテクチャにより、ユーザー間の物理的な距離とリクエストの実行が最小限に抑えられ、レイテンシが大幅に短縮され、パフォーマンスが向上します。
エッジ ランタイムは計算をユーザーに近づけますが、ユーザー固有の情報、セッション トークン、構成の取得など、ほとんどの操作では依然としてデータにアクセスする必要があります。キャッシュ層がなければ、各リクエストは依然として中央データベースへのラウンドトリップを必要とし、レイテンシの利点の多くが無効になります。ここで Global Redis が重要な役割を果たします。頻繁に使用されるデータをエッジにレプリケートし、低レイテンシのアクセスを保証します。
コード例 1:Node.js を使用した PostgreSQL
グローバル Redis によるキャッシュは完璧です。次に、Upstash Redis と Postgresql データベースを使用してキャッシュ アサイド戦略を実装するコード サンプルを見ていきます。
まず、データ ストアへの接続に使用する SDK をインストールする必要があります。
npm install pg upstash/redis
依存関係をインストールしたら、データ ストア、Upstash Redis および Postgres に接続できるようになります。
const { Redis } = require('@upstash/redis'); // Upstash Redis SDK
const { Client } = require('pg');
const redis = new Redis({
url: <UPSTASH_REDIS_REST_URL>,
token: <UPSTASH_REDIS_REST_TOKEN>,
})
const client = new Client({
user: 'username',
password: 'password',
host: 'host',
port: 'port_number',
database: 'database_name',
});
client.connect();次に、データ アクセス層に関数を記述しましょう。この関数は必要に応じて変更できます。
Web サイト上のユーザー情報を userId 別に表示したいとします。この場合、userId をパラメータとして取得する関数が必要です。
async function getUserData(userId) {
// Check cache first
const cachedData = await redis.get(userId);
if (cachedData) {
console.log('Cache hit');
return JSON.parse(cachedData);
}
// Fallback to database
console.log('Cache miss');
const query = 'SELECT * FROM users WHERE id = $1';
const { rows } = await client.query(query, [userId]);
await redis.set(userId, JSON.stringify(rows), { EX: 300 }); // Cache for 5 minutes
return rows;
}ここにあります!この関数はまず、リクエスタのリージョンに最も近い Redis データベースでユーザー情報が利用可能かどうかを確認します。利用できない場合は、Postgresql データベースから要求されたデータをクエリし、返されたデータを Upstash Redis プライマリ リージョンに書き込みます。プライマリ リージョンに書き込まれたデータは、すべてのリードレプリカに自動的にコピーされます。
コード例 2:Python を使用した MYSQL
次に、別の例を見てみましょう。今回も同様のキャッシュ実装を行いますが、今回のメインデータベースはMYSQLになります。また、この関数を Python で作成して、Python ベースのアプリケーションでどのように動作するかを確認します。
いつものように、最初にデータベースの接続に使用する依存関係をダウンロードします。
pip install upstash-redis upstash-redis
これで、クライアントを初期化して接続できるようになりました。
import upstash_redis
import mysql.connector
import json
# Initialize Upstash Redis client
redis_client = upstash_redis.Redis(
url='<your-upstash-redis-url>',
token='<your-upstash-token>'
)
# Initialize MySQL client
db = mysql.connector.connect(
host="<your-mysql-host>",
user="<your-mysql-user>",
password="<your-mysql-password>",
database="<your-database-name>"
)
cursor = db.cursor(dictionary=True)接続の準備ができました。ここで、前のセクションで実装したのと同様の関数を実装します。
def get_user_data(userId):
# Check the cache for the data
cache_data = redis_client.get(key)
if cache_data:
print("Cache hit")
return json.loads(cache_data)
# If cache miss, query the MySQL database
print("Cache miss")
cursor.execute("SELECT * FROM users WHERE key = %s", (userId))
result = cursor.fetchone()
if result:
# Store the data in the cache with a TTL of 1 hour
redis_client.set(key, json.dumps(result), ex=3600)
return result結論
Global Redis をアーキテクチャに統合することにより、特にグローバルに分散された環境において、SQL ベースのアプリケーションのパフォーマンスを大幅に向上させることができます。 Global Redis は、低レイテンシのアクセス、データベース負荷の軽減、エッジ ランタイムとの互換性により、SQL データベースを使用するアプリケーションのパフォーマンスの課題に対処できます。
このブログ投稿では、グローバル Redis を使用したキャッシュの利点を確認し、いくつかの例を検討しました。これらは単なる基本的な例であり、ニーズに応じてさらに拡張できます。
このブログが、グローバル Redis の力を活用し始めるための良いスタートになれば幸いです。
-
Upstash Kafka、Redis、Next.js を使用してリアルタイム チャット アプリを構築する
プロジェクトの説明 このブログ投稿では、ユーザーがメッセージ クライアントとチャット ルームを作成できるメッセージング アプリケーションを作成します。さらに、ユーザーは過去のメッセージにアクセスできるようになります。 プロジェクトは 2 ページで構成されます。最初のページはクライアント登録専用であり、一意の名前を持つ複数のクライアントを作成できます。 クライアントのユーザー名をクリックすると、その特定のユーザーに関連付けられたチャットルーム クライアントに移動します。 チャット アプリケーションのロジックは次のとおりです。 ユーザーはインデックス ページ上に複数のクライアント
-
Redis ZINTERSTORE –ソートされた設定値の共通部分を実行する方法
このチュートリアルでは、redis ZINTERSTORE を使用して、redisデータストアに格納されている2つ以上の並べ替えられたセットの値に対して交差操作を実行する方法について学習します。 コマンド。 セットの共通部分: 集合論では、2つ以上の集合の共通部分は、すべての集合に共通する要素を含む集合です。例: A = {1, 2, 3, 4, 5}B = {4, 5, 6, 7, 8, 9}Intersection of A & B :-A ∩ B = {4, 5} ZINTERSTOREコマンド:- このコマンドは、2つ以上の指定されたソート済みセットの交差