カウント-最小スケッチ:ものを推定する芸術と科学
この投稿は、私の意見では、世界で最もエキサイティングな2つのもの、つまり確率的データ構造とRedisモジュールについてです。どちらかについて聞いたことがあるなら、きっと私の熱意に関係することができますが、地球上で最もクールなものに追いつきたい場合は、読み続けてください。
このステートメントから始めましょう。大規模で低レイテンシのデータ処理は困難です。関連するデータの量と速度により、リアルタイム分析は非常に困難になる可能性があります。その高性能と汎用性により、Redisはこのような課題を解決するために一般的に使用されています。複数の形式のデータをミリ秒未満の遅延で保存、操作、提供できるため、オンライン計算が必要な多くの場合に理想的なデータコンテナになります。
しかし、すべてが相対的であり、正確なリアルタイム分析を実際的に不可能にするほど極端なスケールがあります。複雑な問題は大きくなるにつれて難しくなりますが、単純な問題も同じルールに従うことを忘れがちです。データが大きすぎる、速すぎる、またはデータを処理するのに十分なリソースがない場合、数値の合計のような基本的なものでさえ、大きな課題になる可能性があります。また、リソースは常に有限で高価ですが、データは誰のビジネスのようにも絶えず成長しています。
Count-min Sketchとは何ですか?
カウントミンスケッチ(CMスケッチとも呼ばれます)は確率的なデータ構造であり、その仕組み、さらに重要なこととして、その使用方法を理解すると非常に役立ちます。
幸い、CMスケッチのシンプルな特徴により、初心者は比較的簡単に理解できます(私の友人の多くは、このTop-Kブログをフォローできなかったことがわかりました)。

CMスケッチは数年前からRedisモジュールであり、最近RedisBloomモジュールv2.0の一部として書き直されました。ただし、CMスケッチに飛び込む前に、 anyを使用する理由を理解することが重要です。 確率的データ構造。速度、スペース、精度の三角形では、確率的データ構造はスペースを獲得するためにある程度の精度を犠牲にします。潜在的には多くのスペース !速度への影響は、アルゴリズムとセットサイズによって異なります。
- 精度 :定義上、データの一部のみを保持し、ストレージでの衝突を許可すると、精度が低下します。ただし、ユースケースに基づいて最大エラー率を設定できます。
- メモリスペース :数十億のイベントが記録されるビッグデータの世界では、部分的なデータのみを保存することで、ストレージスペースの要件とコストを大幅に削減できます。
- 速度 :特定の従来のデータ構造は比較的非効率的に動作し、応答時間を遅くします。 (たとえば、並べ替えられたセットはその中のすべての要素の順序を維持しますが、上位の要素だけに関心があるかもしれません。確率的アルゴリズムは部分的なリストのみを維持するため、より効率的で、多くの場合、クエリにはるかに速く答えることができます。
適切な確率的データ構造により、精度の低下と引き換えに、データセット内の情報の一部のみを保持できます。もちろん、多くの場合(銀行口座など)、精度の低下は許容できません。しかし、映画を推薦したり、ウェブサイトのユーザーに広告を表示したりする場合、比較的まれなミスのコストは低く、スペースを大幅に節約できる可能性があります。
基本的に、CMスケッチは、データセット内のすべてのアイテムの数をいくつかのカウンター配列に集約することによって機能します。クエリを実行すると、すべての配列のアイテムの最小カウントが返されます。これにより、衝突によるカウントの増加を最小限に抑えることができます。出現率またはスコアが低いアイテム(「マウスフロー」)のカウントは、エラー率を下回っています。 、したがって、実際のカウントに関するデータはすべて失われ、ノイズとして扱われます。出現率やスコアが高いアイテム(「象の流れ」)の場合は、受け取ったカウントを使用するだけです。 CMスケッチのサイズは一定であり、無限の数のアイテムに使用できることを考えると、ストレージスペースを大幅に節約できる可能性があります。
背景として、スケッチはデータ構造のクラスとそれに付随するアルゴリズムです。定数または劣線形空間を使用しながら、データに関する質問に答えるために、データの性質をキャプチャします。 CMスケッチは、GrahamCormodeとS.Muthu Muthukrishnanによって、2005年の論文“ で説明されました。 改善されたデータストリームの概要:カウント最小スケッチとそのアプリケーション。」
カウント分スケッチ:何をどのように
CMスケッチは、主要なユースケースをサポートするためにカウンターのいくつかの配列を使用します。配列の数を「深さ」と呼び、各配列のカウンターの数を「幅」と呼びましょう。
アイテムを受け取るたびに、ハッシュ関数(単語、文、数値、またはバイナリなどの要素を、セット/配列内の場所またはフィンガープリントとして使用できる数値に変換する)を使用して、アイテムの場所を指定し、配列ごとにそのカウンターを増やします。関連する各カウンターの値は、アイテムの実際の値以上です。問い合わせを行うときは、同じハッシュ関数を持つすべての配列を調べて、アイテムに関連付けられているカウンターをフェッチします。次に、値が膨らんでいる(または等しい)ことがわかっているため、検出した最小値を返します。
多くのアイテムがほとんどのカウンターに寄与することはわかっていますが、自然な衝突(異なるアイテムが同じ場所を受け取る場合)のため、目的のエラー率の範囲内である限り、「ノイズ」を受け入れます。
Count-minスケッチの例
数学は、深さが10、幅が2,000の場合、エラーが発生しない確率は99.9%、エラー率は0.1%であることを示しています。 (これは、一意のアイテムではなく、合計増分のパーセンテージです。)
実数では、つまり、100万個の一意のアイテムを追加すると、各アイテムは500(1M / 2K)の値を受け取ります。それは不釣り合いに思えますが、これはエラー率0.1%の範囲内であり、100万アイテムに対して1,000です。
同様に、10頭の象がそれぞれ10,000回出現する場合、すべてのセットでのそれらの値は10,000以上になります。将来それらを数えるときはいつでも、目の前に象がいます。他のすべての数(つまり、実際の数が1であるすべてのマウス)の場合、この発生の可能性は低く、さらに減少するため、すべてのセットで象と衝突する可能性は低くなります(CMスケッチは最小数のみを考慮するため)。 CMスケッチを初期化するときに深度を増やします。
Count-min Sketchは何に適していますか?
CMスケッチの動作を理解したので、この小さな獣で何ができるでしょうか。一般的な使用例は次のとおりです。
- 2つの数値をクエリし、それらの数を比較します。
- 入荷するアイテムの割合を設定します。たとえば、1%とします。アイテムの最小カウントが合計カウントの1%を超える場合は常に、trueを返します。これは、たとえば、オンラインゲームのトッププレーヤーを決定するために使用できます。
- CMスケッチに最小ヒープを追加し、Top-Kデータ構造を作成します。アイテムを増やすたびに、新しい最小カウントがヒープ内の最小値よりも大きいかどうかを確認し、それに応じて更新します。時間の経過とともに徐々に減衰するRedisBloomのTop-Kモジュールとは異なり、CMスケッチは決して忘れないため、その動作は HeavyKeeperとは少し異なります。 ベースのTop-K。
RedisBloomでは、CMスケッチのAPIはシンプルで簡単です:
- CMスケッチデータ構造を初期化するには: INITBYDIM { key }{幅 }{深さ } またはCMS.INITBYPROB{ key }{エラー }{確率 }
- アイテムのカウンターを増やすには: CMS.INCRBY { key } { item }{増分 }
- アイテムのカウンターで見つかった最小数を取得するには: CMS.QUERY { key } { item }
次のコマンドを使用して、この投稿の上部にアニメーションの例を作成しました。
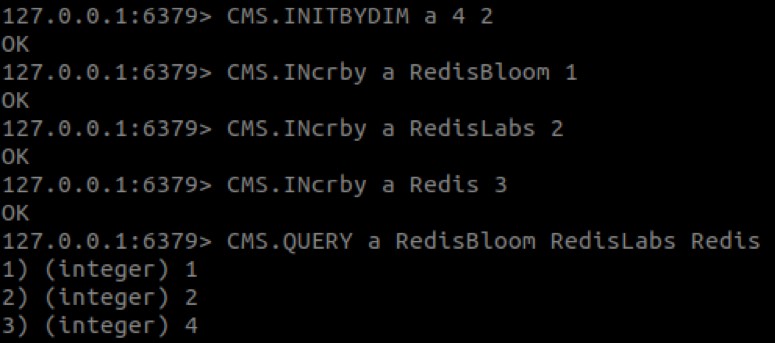
ご覧のとおり、「Redis」の値は3ではなく4です。CMスケッチでは、アイテムの数が増える可能性があるため、この動作が予想されます。
大ざっぱなビジネス
ソフトウェアエンジニアリングはすべてトレードオフを行うことであり、費用効果の高い方法でそのような課題に対処するための一般的なアプローチは、効率を優先して正確さを放棄することです。このアプローチは、設定されたカーディナリティに関するクエリへの回答を効率的に提供するように設計されたデータ構造であるHyperLogLogのRedisの実装によって例示されています。 HyperLogLogは、「スケッチ」と呼ばれるデータ構造のファミリーのメンバーであり、実際の芸術的な対応物と同様に、主題の近似を介して情報を伝達します。
大まかに言うと、スケッチはデータ構造(およびそれに付随するアルゴリズム)であり、データ自体を実際に保存することなく、データの性質、つまりデータに関する質問への回答をキャプチャします。正式に言えば、スケッチは劣線形漸近計算の複雑さを持ち、したがって必要な計算能力やストレージが少ないため、便利です。しかし、フリーランチはなく、効率の向上は回答の正確さによって相殺されます。ただし、多くの場合、エラーをしきい値未満に保つことができる限り、エラーは許容されます。優れたデータスケッチとは、エラーを容易に認めるものであり、実際、多くのスケッチは、ユーザーが定義できるように、エラー(またはエラーの確率)をパラメーター化します。
優れたスケッチは効率的であり、エラーの可能性が高くなりますが、優れたスケッチとは、並行して計算できるスケッチです。並列化可能なスケッチは、データの一部に基づいて独立して作成でき、その部分を意味のある一貫性のある集計に結合できるスケッチです。優れたスケッチの各部分は異なる場所や時間で計算できるため、並列処理により、分割統治法を適用してスケーリングの課題を解決することができます。
よくある問題
前述のHyperLogLogは優れたスケッチですが、特定の種類の質問に答える場合にのみ適しています。 G.CormodeとS.Muthukrishnanによる論文「改善されたデータストリームの概要:カウント最小スケッチとそのアプリケーション」で説明されているように、もう1つの貴重なツールはカウント最小スケッチ(CMS)です。この独創的な矛盾は、分析プロセスの大部分で一般的な構成要素であるサンプルの頻度に関する回答を提供するために考案されました。
十分な時間とリソースがあれば、サンプルの頻度の計算は簡単なプロセスです。各サンプル(見たもの)の観測数(見た回数)を保持し、それを観測の総数で割って、そのサンプルの頻度を取得するだけです。ただし、大規模で低レイテンシのデータ処理のコンテキストを考えると、十分な時間やリソースはありません。回答は、その規模に関係なく、データストリームとして即座に提供される必要があり、サンプリングスペースのサイズが非常に大きいため、各サンプルのカウンターを維持することは不可能です。
したがって、各サンプルを正確に追跡する代わりに、頻度を推定してみることができます。そのための1つの方法は、観測値をランダムにサンプリングし、そのサンプルが一般的に全体の特性を反映していることを期待することです。このアプローチの問題は、真のランダム性を確保することが難しい作業であるため、ランダムサンプリングの成功は、選択プロセスやデータ自体のプロパティによって制限される可能性があることです。そこで、CMSは根本的に異なるアプローチを採用しているため、最初は優れたスケッチの反対のように見えるかもしれません。CMSはすべての観測を記録するだけでなく、それぞれが複数のカウンターに記録されます!
もちろん、ひねりがあり、シンプルであると同時に賢いです。元の論文(および「Count-Minデータ構造を使用したデータの近似」と呼ばれるその軽量版)は、それを説明するのに優れていますが、とにかく要約しようと思います。 CMSの巧妙さは、サンプルを保存する方法にあります。一意の各サンプルを個別に追跡する代わりに、ハッシュ値を使用します。サンプルのハッシュ値は、一定サイズの(ペーパーではdとしてパラメーター化された)カウンターの配列へのインデックスとして使用されます。いくつかの(パラメーターw)異なるハッシュ関数とそれぞれの配列を使用することにより、スケッチは、サンプルに関連するすべてのカウンターから最小値を選択することにより、構造のクエリ中に検出されたハッシュ衝突を処理します。
例が必要なので、データ構造の内部動作を説明するために簡単なスケッチを作成しましょう。スケッチを単純にするために、小さなパラメータ値を使用します。 wを3に設定します。つまり、それぞれh1、h2、h3で示される3つのハッシュ関数を使用し、dを4に設定します。スケッチのカウンターを格納するために、合計12の3×4配列を使用します。 0に初期化された要素。
これで、サンプルがスケッチに追加されたときに何が起こるかを調べることができます。サンプルが1つずつ到着し、s1として示される最初のサンプルのハッシュがh1(s1)=1、h2(s1)=2、h3(s1)=3であると仮定します。スケッチにs1を記録するには'関連するインデックスの各ハッシュ関数のカウンターを1ずつインクリメントします。次の表に、配列の初期状態と現在の状態を示します。

スケッチにはサンプルが1つしかありませんが、すでに効果的にクエリを実行できます。サンプルの観測数はすべてのカウンターの最小数であるため、s1の場合は次のように取得されることに注意してください。
min(array[1][h1(s1)], array[2][h2(s1)], array[3][h3(s1)]) = スケッチは、まだ追加されていないサンプルに関する質問にも答えます。 h 1と仮定します (s 2 )=4、h 2 (s 2 )=4、h 3 (s 2 )=4、s 2のクエリに注意してください 結果は0になります。引き続きs2を追加しましょう。 およびs3 (h 1 (s 3 )=1、h 2 (s 3 )=1、h 3 (s 3 )=1)スケッチに追加すると、次のようになります。
min(array[1][1], array[2][2], array[3][3]) =
min(1,1,1) = 1

考案された例では、h1(s1)とh1(s3)の衝突を除いて、ほとんどすべてのサンプルのハッシュが一意のカウンターにマップされます。両方のハッシュが同じであるため、h1の最初のカウンターは値2を保持します。スケッチはすべてのカウンターの最小値を選択するため、s1とs3のクエリは正しい結果1を返します。ただし、最終的には、十分な衝突が発生すると発生すると、クエリの結果の精度が低下します。
CMSの2つのパラメータ(wとd)は、そのスペース/時間要件、およびエラーの確率と最大値を決定します。スケッチを初期化するためのより直感的な方法は、エラーの確率と上限を指定して、wとdに必要な値を導き出すことです。同じパラメータとハッシュ関数を使用して配列を作成する限り、任意の数のサブスケッチを配列の合計として簡単にマージできるため、並列化が可能です。
カウント分スケッチに関するいくつかの所見
Count Min Sketchの効率は、その要件を確認することで実証できます。 CMSのスペースの複雑さは、w、d、および使用するカウンターの幅の積です。たとえば、0.01%の確率で0.01%のエラー率を持つスケッチは、10個のハッシュ関数と2000個のカウンター配列を使用して作成されます。 16ビットカウンターの使用を想定すると、結果のスケッチのデータ構造の全体的なメモリ要件は40KBになります(観測の総数といくつかのポインターを格納するには、さらに2バイトが必要です)。スケッチの他の計算面も同様に満足のいくものです。ハッシュ関数の生成と計算は安価であるため、読み取りまたは書き込みのいずれの場合でも、データ構造へのアクセスも一定時間で実行されます。
CMSにはまだまだあります。スケッチの作者は、他の同様の質問に答えるためにスケッチをどのように使用できるかも示しています。これらには、パーセンタイルの推定とヘビーヒッター(頻繁なアイテム)の特定が含まれますが、この投稿の範囲外です。
CMSは確かに優れたスケッチですが、完璧を達成するのを妨げるものが少なくとも2つあります。 CMSについての私の最初の予約は、バイアスがかかる可能性があるため、少数の観測値でサンプルの頻度を過大評価する可能性があることです。 CMSのバイアスはよく知られており、いくつかの改善が提案されています。最新のものは、Count Min Log Sketch(G.PitelおよびG.Fouquierの「近似カウンターで近似カウント」)です。これは、基本的にCMSの線形レジスタを対数レジスタに置き換えて、相対誤差を減らし、幅を増やさずにカウントを増やすことができます。カウンタレジスタの数。
上記の予約はすべての人によって共有されますが(データ構造を取得する人だけですが)、私の2番目の予約はRedisコミュニティ専用です。説明するために、Redisモジュールを紹介する必要があります。
Redisモジュール
Redis Modulesは、今年初めにRedisConfでantirezによって発表され、文字通り私たちの世界をひっくり返しました。モジュールを使用すると、サーバーにロード可能なダイナミックライブラリにすぎず、RedisユーザーはRedis自体よりも速く移動し、これまで夢にも思わなかった場所に移動できます。この投稿は、モジュールとは何か、モジュールの作成方法の紹介ではありませんが、この投稿(およびこの投稿とこのウェビナー)はそうです。
非常に便利なことは別として、Count MinSketchRedisモジュールを書きたかった理由はいくつかあります。その一部は学習体験であり、一部はモジュールAPIの評価でしたが、ほとんどの場合、新しいデータ構造をRedisにモデル化するのはとても楽しかったです。このモジュールは、スケッチに観測を追加し、クエリを実行し、複数のスケッチを1つにマージするためのRedisインターフェースを提供します。
このモジュールは、スケッチのデータをRedis文字列に格納し、ダイレクトメモリアクセス(DMA)を使用してキーの内容を内部データ構造にマッピングします。まだ徹底的なパフォーマンスベンチマークを実施していませんが、ローカルでテストしたときの最初の印象は、コアのRedisコマンドと同じくらいパフォーマンスが高いということです。他のモジュールと同様に、countminsketchはオープンソースであるため、試してハックすることをお勧めします。
サインオフする前に、約束を守り、CMSに関するRedis固有の予約を共有したいと思います。他のスケッチやデータ構造にも当てはまる問題は、CMSでは、使用する前にセットアップ/初期化/作成する必要があることです。 CMSパラメータの設定など、必須の初期化段階が必要な場合、Redisの基本的なパターンの1つが壊れます。データ構造はオンデマンドで作成できるため、使用前に明示的に宣言する必要はありません。モジュールをよりRedisっぽく見せ、そのアンチパターンを回避するために、モジュールは、新しいスケッチが暗黙的に暗示されている場合(つまり、存在しないキーでCMS.ADDコマンドを使用する場合)にデフォルトのパラメーター値を使用しますが、新しいスケッチを作成することもできます指定されたパラメータを持つ空のスケッチ。
確率的データ構造、つまりスケッチは、ビッグデータの増加とレイテンシーバジェットの縮小に効率的かつ十分に正確な方法で対応できる素晴らしいツールです。この投稿で言及されている2つのスケッチ、およびブルームフィルターやTダイジェストなどの他のスケッチは、現代のデータ管理者の武器庫で急速に不可欠なツールになりつつあります。モジュールを使用すると、ネイティブ速度で動作し、データにローカルアクセスできるカスタムデータ型とコマンドを使用してRedisを拡張できます。可能性は無限であり、不可能なことは何もありません。
Redisモジュールとその開発方法についてもっと知りたいですか?確率的かどうかに関係なく、Redisで議論または追加したいデータ構造はありますか? Twitterアカウントまたはメールで、お気軽にご連絡ください。高可用性を実現しています🙂
-
DBAとデータアーキテクトの進化
企業の顧客、従業員、およびパートナーがユーザーフレンドリーなシステムを介してデータに簡単にアクセスできる場合、データベース管理者とデータアーキテクトの2人に感謝します。十分に構築されたデータベースが潜在的に数千または数百万のユーザーに対して確実かつ安全に機能することを保証することは大きな責任であり、あらゆる業界の企業は、データアーキテクトとDBAに依存して、それらを使用するすべてのユーザーのニーズを満たすデータネットワークを設計および監視します。 ビジネスコミュニティのデータニーズが急増するにつれて、最新のデータベーステクノロジーに対応するために必要なスキルも拡大しています。これらの役割の
-
科学を疑問視する技術
ニュートンがリンゴが地球に落ちた経緯を自問していなかったら?もしコロンブスが、地球が平らではなく丸いことを証明するために戦わなかったら?もしインターネットが存在しなかったとしたら?重力の概念が存在しなかったとしたら、私たちは地球を離れることはなく、月はおとぎ話の一部に過ぎなかったでしょう.したがって、すべてのイノベーションの発見は一連の質問から始まります。 「科学者とは、正しい答えを出す人ではなく、正しい質問をする人です。」、Claude Levi-Strauss. 正しい質問をすることは、高潔な科学の核心です。洞察に満ちたクエリは、受け入れられている規範やモデルに挑戦し、概念についての考