ベクトル類似性検索のためにRedisを再発見する
RedisDays NY 2022で、新しいベクトル類似性検索(VSS)機能の公開プレビューを発表しました。 VSSはRediSearch2.4の一部であり、Docker、Redis Stack、およびRedisEnterpriseCloudの無料および固定サブスクリプションで利用できます。
この記事では、ベクトルの類似性の基本とそのアプリケーションについて説明し、リソースを共有してRedisVSSの使用を開始します。
簡単に言えば、2つ以上のベクトルがどれだけ異なる(または類似している)かを示す尺度です。ベクトルを数値のリストと考えてください。
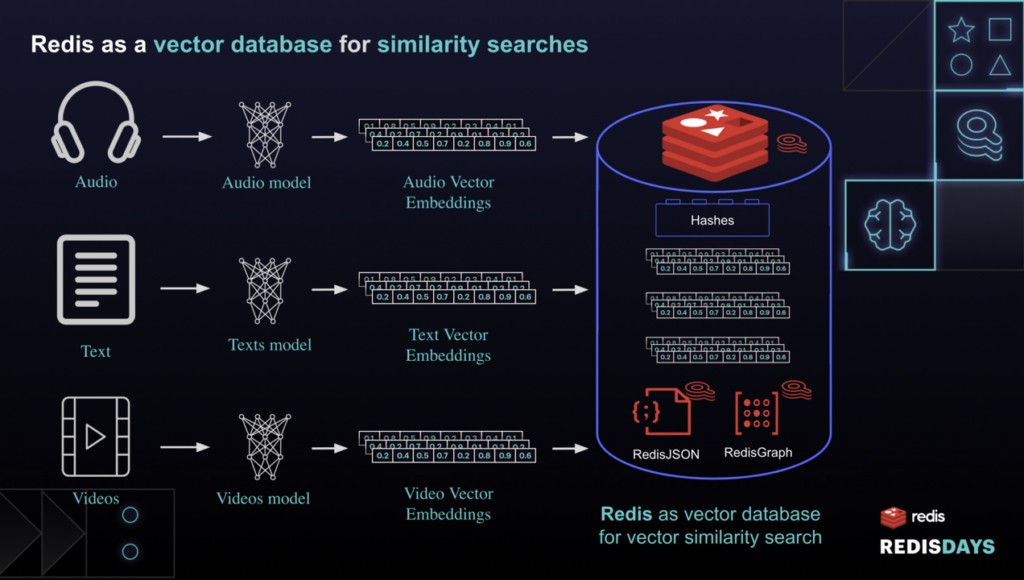
基本的に、ベクトル検索を使用すると、開発者はオーディオ、自然言語、画像、ビデオクリップ、音声録音、およびその他の多くの種類のデータに基づいて情報を取得できます。非構造化データを検索することで、VSSは高度な類似性検索エクスペリエンスを構築するための基盤となるテクノロジーになります。
AIの進歩により、データサイエンティストは、ほぼすべてのデータ「エンティティ」をそのベクトル表現に変換できるモデルを構築できます。ここでのエンティティは、トランザクション、ユーザープロファイル、画像、音声、長いテキスト(文または段落)、時系列、またはグラフである可能性があります。これらはいずれも、「埋め込み」とも呼ばれる「特徴ベクトル」に変換できます。
これらの埋め込みはどういう意味ですか?ベクトル埋め込みは、データの数値表現です。これらは、コンピューターとデータベースが簡単に比較できる方法で、エンティティの最も重要な機能をキャプチャします。ここで興味深いのは、モデルが2つのエンティティに対して2つの類似した埋め込み(ベクトル)を生成する場合、2つの元のエンティティが何らかの基本的な方法で類似していると推測できることです。
全くない!開発者がテキスト、画像、または時系列データから埋め込みを生成できるようにする、無料で利用できるAIモデルとライブラリがいくつかあります。たとえば、HuggingFace Sentence Transformersを使用して文の埋め込みを生成し、Img2Vecを使用して画像の埋め込みを生成し、FacebookKatsを使用して時系列データの埋め込みを生成できます。 AI / MLの実践者は、データエンティティの「高密度」機能表現(埋め込み)を生成するという概念に精通しています。これらの特徴ベクトルをRedisに保存し、類似性検索を実行できるようになりました。

ベクトル類似性検索に依存する、操作する日常のアプリケーションがいくつかあります。
eコマースWebサイトでの視覚的検索から、自動チャットボット/ Q&Aシステム、および複数のタイプのレコメンデーションシステムまで。より一般的には、VSSは、価値を解き放つためにリアルタイムで類似性を見つけることが不可欠なアプリで役立ちます。一般的な使用例を以下に示します。
– eコマースの推奨事項:視覚的類似性および/または意味的類似性を使用して、高度な検索エクスペリエンスと製品の推奨事項を強化します
–意味的類似性:高度な検索エクスペリエンス、チャットボット、さらには質問応答システムを構築します
–時系列データの類似性:過去のパターンの類似性に基づいて、病気の蔓延パターンまたは取引の機会の類似性を発見します
–グラフデータの類似性:アクターまたはネットワークの異なる(おそらく無関係な)セット間での接続の類似したパターンを明らかにします。
–トランザクションの類似性:以前に検出された詐欺/脅威の試みとの類似性に基づいて、潜在的な詐欺または脅威を検出します
–ユーザープロファイルまたは製品の類似性:パーソナライズされた推奨事項を生成します。埋め込みデータによって明らかにされたパターンに基づいて、顧客のセグメンテーションを改善します
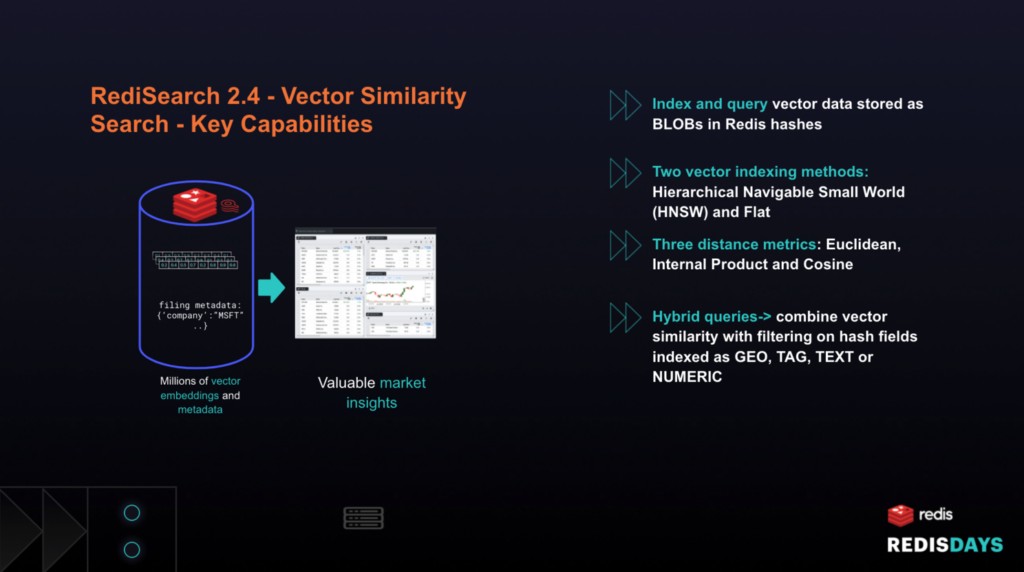
RediSearchは、RedisハッシュまたはJSON形式で保存されたRedisデータのクエリ機能、セカンダリインデックス作成、および全文検索を提供するRedisモジュールです。 Redis 2.4では、Redisはベクトル類似性検索のサポートを導入しました。
RediSearch 2.4を使用すると、Redis開発者は次のことができます。
–RedisハッシュにBLOBとして保存されたインデックスおよびクエリベクターデータ
–2つの一般的なインデックス作成方法を使用します:FLATとHNSW
– 3つの一般的なベクトル距離メトリックを使用します:正弦、内部積、およびユークリッド距離
– GEO、NUMERIC、TAG、またはTEXTデータに対して、ベクトルの類似性と従来のRediSearchフィルタリング機能を組み合わせたハイブリッドクエリを実行します。 eコマース設定でのハイブリッドクエリの一般的な例は、「GEOの場所で、価格範囲内で利用可能なアイテムに限定された、特定のクエリ画像に視覚的に類似したアイテムを見つける」です。
Pythonが便利な場合は、次のことを試してください。
–パブリックAmazonデータセットでの視覚的および意味的類似性
–FinancialNewsの記事における感情分析と意味的類似性
Javaの場合、インデックスの作成、データのロード、クエリの方法を示すこの基本的なデモを試すことができます。
これら2つのRedisDays2022セッションのリプレイを見てみてください。
–基調講演 :「金融サービス」アプリケーションにリアルタイムAIを注入する
– 舞台裏: AIを使用して企業ファイリングに埋め込まれた取引シグナルを明らかにする
セッションはオンデマンドで視聴できるようになりました。 「ベクターの操作」に関するRediSearchのドキュメントはいつでも確認できます。

RediSearch2.4を使用してRedisデータベースを作成する簡単な方法は3つあります。
ターミナルから、次のいずれかで取得できます。
1)Docker –「dockerrun -p 6379:6379 redislabs / redisearch:2.4.5」
2)Redisスタック–「brewinstallredis-stack」(Mac OSから)。その他のオペレーティングシステムについては、「RedisStack入門」をお試しください
3)最後に、RedisEnterpriseCloudで無料のサブスクリプションを作成することもできます
Redis Enterprise Cloudサブスクリプションルートを使用する場合は、必ず「Redisスタック」を使用してください。 」オプションにはRediSearch2.4が含まれています。
-
ストラップ用のサーバーレスRedisキャッシング
プロジェクトを時間どおりに提供するということは、通常、既存のテクノロジーを可能な限り活用する必要があることを意味します。カスタム実装につながるすべての決定は、独自のソリューションを維持する必要があることも考慮する必要があります。これが、Strapiのようなオープンソースツールが次のプロジェクトのRESTAPIを構築するための方法である理由です。 ストラピは最先端のヘッドレスCMSです。グラフィカルインターフェイスを使用してスキーマを定義できるため、技術者でない人でもデータをモデル化できます。開発チームは、バックエンドの実装について心配することなく、Webアプリとモバイルアプリの構築と新機能の
-
REDIS(REmote DIrectory Server)–Redisチュートリアル
Redisは、オープンソース(BSDライセンス)のNoSQLデータベースです。これはインメモリデータベースです 、Key-Valueストアの概念に基づく 。 Redisはデータ構造ストアとも呼ばれます 。 すべての用語を1つずつ理解しましょう:- Key-Valueデータストア:- これはデータストレージパラダイムであり、データベースに保存されている値を一意に識別するキーに対する値としてデータが保存および取得されます。 Redisは巨大なハッシュテーブルと見なすことができます。 インメモリデータベース:- インメモリデータベースは、すべてのデータをメインメモリ(RAM)に格納するデー